



•
원문 글의 저자 : Swapna M (Principal Product Lead) at Microsoft
•
원문 글의 업로드 날짜 : 20230322
•
본 글은 위 블로그의 내용을 한글로 번역하여 작성한 내용입니다. 상세한 내용은 원문 블로그를 참고하시길 바랍니다.
•
아래와 같은 내용을 포함하고 있습니다
1.
Enterprise Search vs. Customer Search (like Google) 비교
2.
LLM의 역할
3.
Enterprise Search의 발전 역사 : from “Keyword Search” to “Cognitive, Conversational Search”
4.
현재 Enterprise Search의 문제점들과 LLM의 효과
5.
검색 질의를 활용하는 3가지 사용자 의도
6.
진화하는 사용자 검색 경험
7.
Enterprise Search의 미래 모습
8.
성공적인 검색을 측정하는 요소들
Enterprise Search (Glean) vs. Consumer Search (Google)
왜 Enterprise Search는 어려운가?
1. Usage frequency & Interaction (Enterprise Search)
•
적은 사용자 : 회사 혹은 조직 내에 한정되기에, 비교적 작은 사용자를 가진다.
•
적은 수준의 usage frequency/engagement
•
학습하기 어려운 Feedback loops : 학습하거나 빠르게 적응하기에는, 길고 적은 빈도로 발생
2. Number of webpages & content involved
•
Consumer Search
◦
12B에 달하는 엄청나게 많은 웹사이트가 존재하며, 모든 insight/answer 들이 반복해서 등장하기에 검색 관련성을 높여주게 되고, 이는 더욱 정확하고 관련성 높은 검색 결과를 만들어 줌.
◦
수십~수백만의 사용자들이 활용
•
Enterprise Search
◦
10~10000 개의 페이지들이 존재하며, 정확한 답변은 한번만 등장하는 경우가 있고, 이는 문장/문단/문구 일 수 있다.
◦
이러한 답변은 오직 몇몇 사용자에 의해서만 찾아진다.
⇒ 학습할 데이터가 매우 적기 때문에 어려운 문제가 된다.
LLM (Large-scale Language Model; like ChatGPT)의 역할
아래와 같은 특징들은 협업/생산성에 도움을 준다.
•
사용자 검색 의도 파악
•
번역
•
컨텐츠 생성
•
요약 (대화, 이메일, 웹페이지 등)
•
컨텐츠 증강 (Content Augmentation)
Evolution of Enterprise Search
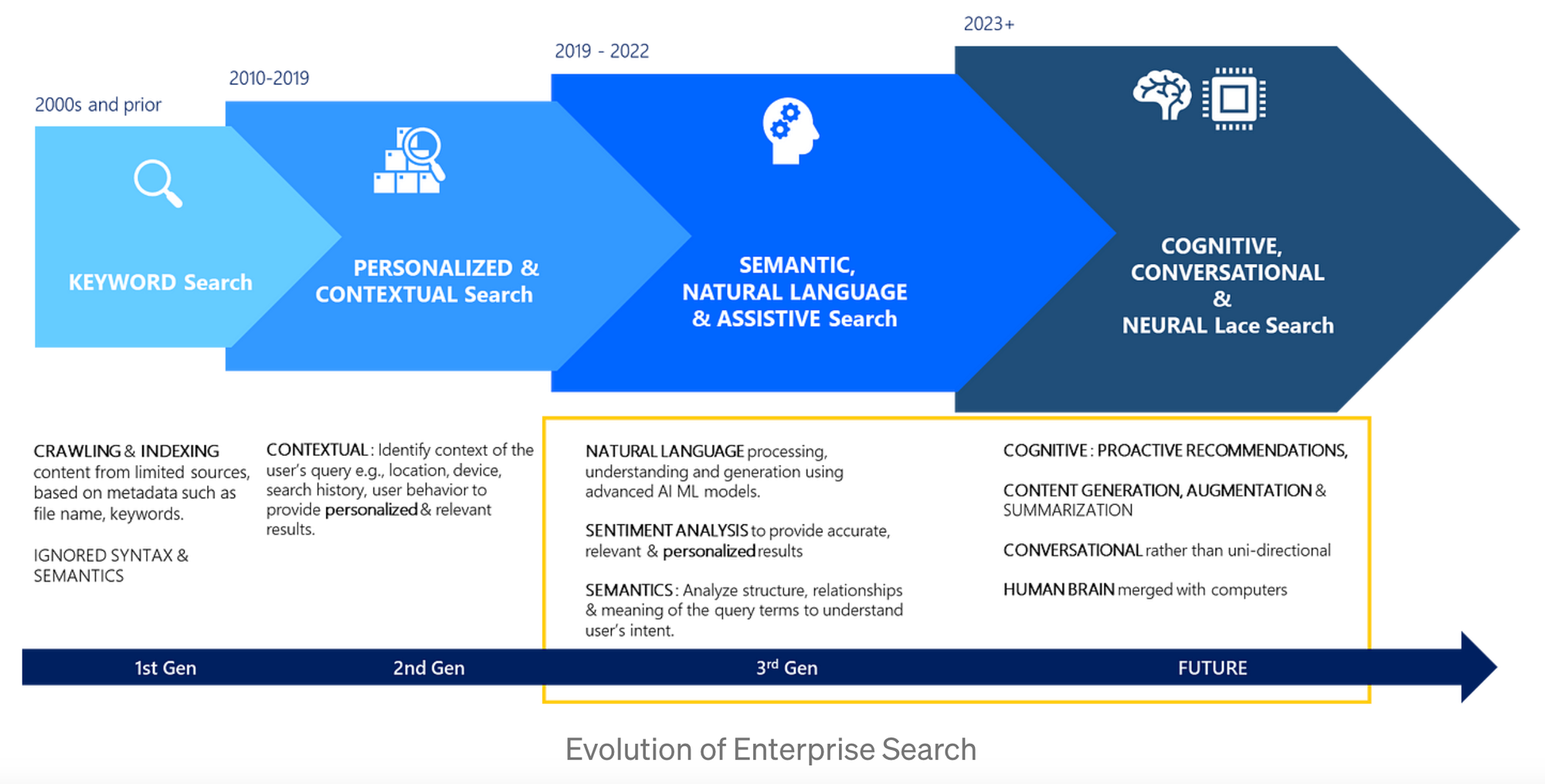
1. 2000s and prior : Keyword Search
•
syntax (의미와 맥락을 만들기 위한 단어들과 문구들의 조합) 무시
•
semantics (표현에 담겨진 의미) 무시
•
문서, 파일 등과 메타 데이터를 모두 활용함
2. 2010~2019 : Personalized & Contextual Search
•
아래의 정보를 활용하여 질의의 맥락을 파악하기 시작
◦
과거 검색 기록
◦
과거 행동
◦
device, location 등의 사용자 attributes
◦
사용자가 속한 cohort
3. 2019~2022 : Semantic, Natural Language & Assistive Search
•
ML 모델을 적극적으로 활용하기 시작
◦
유저 질의의 의도/감정 분석
◦
유저 질의의 구조 분석
◦
유저 질의 내 term들의 관계 혹은 의미 파악
•
Assistant & task automation 개념 도입
◦
manual intervention을 최소화하여 workflow를 자동화하는데 도움을 줌
4. 2023~ : Cognitive, Conversation Interface (ChatGPT) & Neural Laced Search
•
Conversation Interface (ChatGPT type)
◦
검색 질의를 Key Entities로 분해
◦
정확하게 유저 의도 파악
◦
여러 파편화 되어있는 데이터로부터 관련된 개인 정보들을 추출
•
Pro-active Recommendations
◦
관련된 컨텐츠 요약
◦
컨텐츠 증강 (Content Augmentation)
◦
컨텐츠 생성
•
5년 내 미래: “Neural Laced Search” (Human Brain Merged with Computers)
◦
당신의 생각은 컴퓨터로 전달될 것이며, 점차 진화하여 가장 완벽한 답변을 찾게 될 것 (마음 속 질문들을 좀 더 심사숙고하게 됨)
Major Challenges Today in Enterprise Search & Impact of LLM (like ChatGPT)
미래에 어떻게 변할 것인가를 이해하기 위해서는, 현재의 문제점들을 파악할 필요가 있음
+
LLM(Large-scale Language Model)이 어떻게 각 문제마다 도움이 되는가?
1. Search Completeness
•
대부분의 조직에서는, 검색 index는 오직 40%~60%만이 완성되어 있음.
•
새로운 Document types과 Sources들 : Figma, Powerbi, Wikis 등등 새로운 플랫폼의 연결
⇒ (LLM) 매우 큰 스케일의 컨텐츠 Mining을 가능하게 하며, 넒은 범위의 Source와 Entity types로부터 완전한 답변을 찾을 수 있도록 해준다
2. Search Relevance
•
사용자들은 지속적으로 DSAT (Dissatisfaction)을 표현하며, 정확한 답변/사람/파일들을 찾는데 실패를 겪게 됨
⇒ (LLM) direct and semantic powered 정답을 제공하는 것에 의해 관련성을 더 높일 수 있음
3. Assistive Search
•
오늘날 사용자들은 여러개의 결과 중에 그들이 정말 찾고자 하는 정보를 추출하는데 어려움을 겪음
⇒ (LLM) 사용자들을 위한 정보 추출 및 요약을 통해, 사용자들이 그들의 workflow들을 달성하는데 있어서 시간을 아낄 수 있게 도와줌
4. Persona-based Search
•
오늘날 Enterprise Search는 조직 내 직원의 다양한 personas/roles을 이해할만큼 충분히 지능적이지 않음.
•
People/Persona-based search들에 대한 결과는 실패하는 비율이 매우 높음.
⇒ (LLM) 직원의 Role, Work Profile, 그리고 다른 상세한 개인적 정보들로부터 관련된 정보들을 파악/처리/추출 할 수 있음
5. Task Completion in Search
•
오늘날 직원들은 업무들을 달성하기 위해 수동으로 검색 & 액션들을 취해야 함.
⇒ (LLM) “특정한 전문지식을 가진 적합한 사람을 찾기, 대화 시작, 미팅 예약, 교육 스케줄링, 컨텐츠 요약 및 증강 등” 직접적으로 업무 달성을 도와줄 수 있음.
User Intents
사용자 측면에서, 검색 질의는 3가지의 주된 의도를 가지고 있음.
1. Find
•
Workflow 중간에 어떤 insight/answer를 빠르게 찾고자 함
•
Document / File / Presentation / Conversation 내부에서 이러한 결과들을 활용할 수 있음
•
사용자들의 주된 목적은, “document 작성 & 이메일 작성 & 대화하는 동안 의사결정 등” 업무를 완성시키는 것에 있음
◦
이를 위해서는, workflow 내에 특정한 정답을 찾을 필요가 있음.
2. Re-Find
•
이전에 참고했었던, 이메일/사람/파일/문서 혹은 정답을 빠르게 다시 찾고자 함
•
사용자는 어딘가에 정답들이 존재한다는 것을 알고 있는 상황. (e.g. 그들이 이전에 보내거나 받았던 이메일들)
3. Research
•
일하는 도중 최소한 30~40%의 시간은 “Project / Business Proposal, Product Pitch 혹은 다른 Requirements과 관련된 정보들”을 찾는데 소모됨
•
Research는 애매한 표현이지만, 사용자가 1일/1주/1달 내 특정 기간 동안 프로젝트를 위해 수행하는 모든 workflow들을 포함.
◦
이러한 종류의 것들은 “여러 종류의 데이터를 소화”하거나 “문서 혹은 프리젠테이션에 사용할 정보를 추출”하기 위해 매우 많은 시간과 에너지를 소모함
User Expectations are evolving
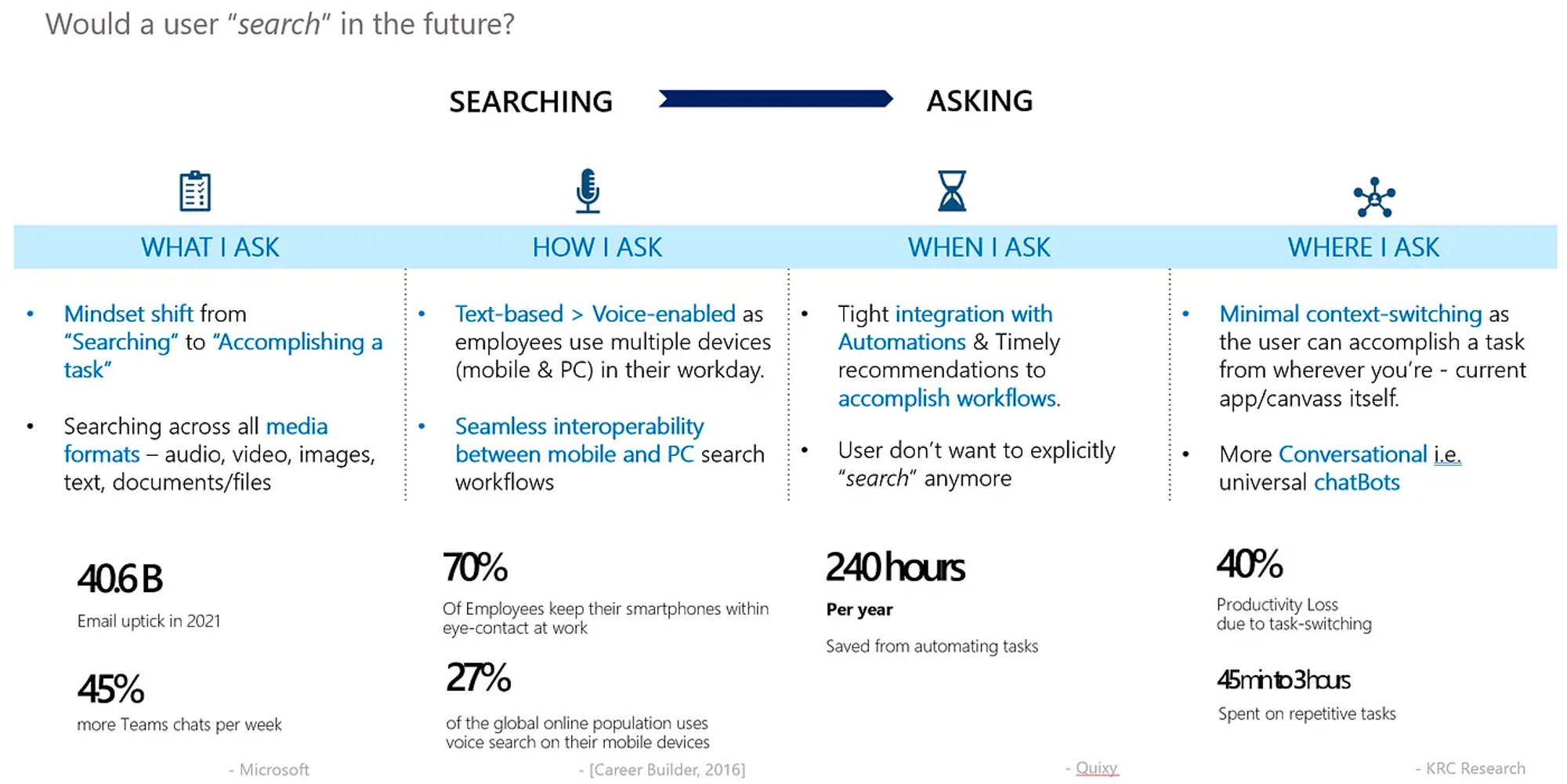
새로운 기술들이 사용자들에게 노출되면서, 사용자들은 이에 빠른 속도로 적응하고 있고, 이에 따라 사용자의 검색 경험은 발전하고 있음.
1. What I ask: “검색” → “업무 완수”
•
“검색” 에서 “업무 완수” 로 변화
◦
직장인 하루의 80%는 작업 완수에 대한 일을 진행함
▪
e.g. 이메일/회의록/노트/사업문서 작성
◦
이제는 더이상 단순히 답을 찾기위해 질문하는 것이 아닌 부드럽게 일과 업무를 완수하는 것을 기대함.
•
컨텐츠 Source와 Type의 확장
◦
질의와 관련해 깊은 insight들을 줄 수 있는 “Audio / Video / Images / Text”로 “질의의 목적이 되는 Content와 Context”가 확장됨
2. How I ask: “음성” & “모바일”
3. When I ask: “주도적인 추천” & “자동화”
•
적절한 타이밍에 “주도적인 추천 (Proactive Recommendation)”과 “미리 완료된 업무들”(Automations)이 검색 결과에 결합되어야 함.
◦
사용자가 workflow를 위해 문맥 전환 (Context-switching) 하는 것을 최소화
•
더 확장된 형태에서는, 이전 사용자의 행동을 기반으로, 사용자의 Needs가 미리 예측되어 업무가 “하루의 특정한 시점, 주간/월간 특정한 날짜”에 자동적으로 완성되어야 함
◦
더이상 사용자는 검색을 별도로 하기를 원하지 않음.
4. Where I ask: “Minimal Context-switching” & “Conversational”
•
오늘날 사용자들은 “Slack/Teams/Gmail/Outlook/Wiki” 등 그들이 사용하는 플랫폼이나 툴 위에서 검색이 답변되거나 업무가 완수되기를 기대함.
생산성 감소의 40%는 업무전환 (task-switching)에서 옴.
— KRC Research
◦
이로인해, 특정한 insight를 얻기 위해 다른 플랫폼이나 앱으로 문맥 전환 (Context-switching) 것이 불필요해짐
•
검색 방식이 “단방향 (Uni-directional)” 에서 “대화형식 (Conversational)” 로 변화 (Like ChatGPT)
◦
모든 플랫폼에 걸쳐서 문맥을 이해하고 가장 관련된 insight를 제공하는 “범용 챗봇”이 보편적으로 인정받는 표준이 됨.
Tasking Enterprise Search to the next level
1. Search needs to break
•
전통적인 workflow 예시 : Powerpoint에서 비지니스 제안서를 작성하다가 중간에 관련된 자료를 얻기 위해 웹에 갔다가 다시 ppt로 돌아와서 삽입
•
현재의 새로운 workflow 예시 : Powerpoint 내부에 “search bar”를 통해 enterprise search가 이루어지고 바로 관련 자료를 얻을 수 있음
◦
이는 power-user 거나 이러한 기능이 존재한다는 것을 아는 사람들만 이용할 수 있음
•
미래 with LLM : “사용자들이 검색을 찾아가는 것이 아닌 검색이 사용자를 찾아오게 하자”
◦
검색의 메커니즘을 처음부터 다시 만드는 것이 필요.
2. Understanding User Intent
•
전통적인 검색 방식 : 원하는 결과를 찾을 때까지 검색 질의를 변경
•
미래 with LLM : “유저 질의를 분해하고, 의도를 추출하며, 다양한 데이터 소스 중 가장 적절한 것으로부터 insights를 요약하고 결합하는 것”
◦
현실의 실제 검색은 매우 복잡하고 지저분하고, LLM은 이러한 지저분한 사람의 프로세스를 우회할 수 있도록 도와줌.
3. Frontend UX vs. Under-the-Hood operations
•
직원들은 하루에 여러 시나리오를 경험하게 됨
◦
말을 걸어야 하는 사람을 찾거나, 일주일 전에 미팅했던 사람을 찾는 것
◦
특정 주제에 대해 본격적인 연구를 진행하기 위해 특정한 파일아니 자료를 찾는 것
•
미래 with LLM : 사용자는 Frontend에서 자신의 검색 경험을 통제 할 수 있어야 하며 (주어진 시간에 어떤 업무를 달성해야하는가), 적절한 시기에 관련된 정보를 제공해주는 모든 다른 세부사항들은 뒷단에서 수행되어야만 하고 (Under-the-hood), 이러한 과정은 부드럽고 흠없이 이루어져야 함.
◦
Backend : 사용자가 “현재 무언가를 빠르게 찾는 것”인지 아니면 “동일한 맥락아래 여러 질문들에 대해 정확한 답들을 찾는 연구를 위한 과정”인지 파악
4. Platform Agnostic
•
탈중앙화 검색 경험 (Platform Agnostic)
◦
사용자가 어디에 있는지, 하루 중 특정 시간에 workflow 중 어떤 과정에 있는지에 따라 관련된 개인화된 insight를 제공해야 함
◦
여러 endpoints / 플랫폼에 걸쳐서 활용될 수 있는 서비스
•
회사 혹은 조직이 집중하고 있는 LOB (Line of Business) 영역 (Sales, Marketing, HR, Legal, Tech Support 등)에 따라 맞춤형 검색 경험이 필요할 수 있음
◦
하지만, 각 맞춤형 검색들이 활용하는 구성 요소들은 회사 전체에 걸쳐서 표준화되어야 함 & 사용자들이 어떤 상황에 있든지 사용자들에게 일관성있는 검색 경험 제공
5. Creative ways to solve Hallucination rates
•
AI Hallucination?
“A hallucination occurs in AI when the AI model generates output that deviates from what would be considered normal or expected based on the training data it has seen.”
— Greg Kostello, CTO and Co-Founder of AI-based healthcare company Huma.AI
◦
AI가 의미없는 그럴싸하게 들리는 랜덤한 거짓말을 생성
◦
이미지, 텍스트, 오디오 등에 미묘한 변화가 전체 시스템이 존재하지 않는 것들을 인지하도록 만듦
•
검색에서 문제가 되는 상황
◦
공식적인 문서에서 AI를 통해 생성한 insight가 유효하지 않은 결과를 만들었을 때
◦
검색 workflow에서 AI가 추천한 것들이 신뢰하지 못하는 것으로 판별되었을 때
MS 에서 시도한 방식 : Creative/Balanced/Precise 세가지 모드를 제공
6. Admin controls are next bet
•
보통 관리자가 조직 내에서 검색이 잘 동작하는지 모니터링하고, 검색 실패 패턴들을 찾아내며, 관련성을 조절하고, 두음문자/줄임말이나 새로운 컨텐츠를 추가하는 작업을 함
•
미래 with LLM : 운영 부담 없이 AI를 업데이트/배포할 수 있으며, 이는 관리자의 부담을 줄여줌 ⇒ 모든 조직은 개인화된 검색 경험을 제공하되, 관리 예산과 시간을 줄일 수 있음
◦
핵심 자료의 자동화된 레이블링
◦
새로운 정답들과 자료들을 추가
◦
조직 내 직원들의 사용 패턴으로부터 검색 관련성을 자동 조절
◦
“주도적인 추천 (Proactive Recommendation)”과 “미리 완료된 업무들”(Automations)” 를 이용한 업무 수행
7. Referencibility
•
AI Hallucination 효과를 줄이기 위해, 정답들 / insights / 여러 데이터 소스들로부터의 결과들을 근거로 두는 것이 필수적임
◦
원본 자료가 유효한 검증된 웹사이트 / 포탈 / 긴 문서 등 필요
◦
LOB (Line of Business) 영역 (Sales, Marketing, HR, Legal, Tech Support 등)에 따라 그들의 포탈 & wiki 들은 여전히 검증된 자료들을 제공하기 위해 존재할 필요가 있음
8. Discoverability of usecase-specific bots
•
많은 조직들이 usecase-specific 챗봇들을 이미 보유하고 있음
◦
CS bot, tech support bot, HR bot 등
•
AI 모델들은 챗봇의 능력을 향상시키는 동시에, 이미 존재하는 챗봇들에 대한 검색 용이성(Discoverability)을 향상시킬 수 있음
◦
e.g. 검색을 통해 현재 존재하는 챗봇들을 빠르게 탐색 & 접근할 수 있고, usecase-specific insight들 (개인 월급, 이민 관련 질의 등) 로 이어질 수 있도록 하여 생산성 증진에 기여
Measuring Search Success
•
검색 실패율을 낮추기
•
재질의 비율을 낮추기
•
소요 시간 절약
•
사용 만족도 (NSAT; Net User Satisfaction) 높이기