.png&blockId=c89df1da-e628-4036-a032-3038717dc316&width=3600)

•
ChatGPT로 인해 AGI 시대로 들어서면서, LLM Ecosystem 환경이 형성되었고, 이 중 Open-source들을 위주로 Foundation Model, Instruct Data, Code 등을 소개하는 문서입니다.
•
2023년 5월 5일에 작성된 version입니다.
•
주로 ChatGPT 이후 등장한 LLM들과 Instruct Data, 그리고 학습 Pipeline Code 등을 다루었습니다. (+Commercial 여부 등록)
•
모델 중에 GPT-NeoX를 활용한 것들이 있기에, GPT-Neo부터 등록해놓았습니다.
•
이후에 추가로 공개되는 모델이 있는 경우 추가할 예정이긴하지만, 언제 진행될지는 미정입니다.
•
질문이나 문의사항 & 공유하고 싶으신 내용들이 있다면, 언제든 댓글이나 이메일로 알려주시면 감사하겠습니다.
1. LLM Ecosystem 이란?
2. LLM Ecosystem: Open-Source Model/Data/Code (since ChatGPT)
Table
Search
이름
출시일
모델 크기
Affiliation
Fine-tuning Method
Commercial
새롭게 제공된 Resource
데이터
Note
2021-03
EleutherAI
- the Pile (영어 only; 825GB)
- 학습 및 테스트 코드 : https://github.com/EleutherAI/gpt-neo
◦ DDP 라이브러리 mesh-tensorflow 기반 학습
◦ DL framework : TF
2022-04
20B
EleutherAI
Model
- the Pile (영어 only; 825GB)
- paper
- 학습 및 테스트 코드 : https://github.com/EleutherAI/gpt-neox/ from scratch, LLM 학습 및 분석 코드
◦ NVdia Megatron https://github.com/NVIDIA/Megatron-LM & DDP 라이브러리 DeepSpeed 기반 학습
◦ DL framework : PyTorch (이때부터 TF → pytorch로 옮김)
2022-05
175B
MetaAI
Model
- RoBERTa Data (BookCorpus, Stories, CCNews v2)
- the Pile (CommonCrawl, DM Mathematics, Project Gutenberg, HackerNews, OpenSubtitles, OpenWebText2, USPTO, Wikipedia)
- PushShift.io Reddit (only longest chain of thread; 66%)
→ English text 위주로 추출 (CommonCrawl 내부에 non-English data 조금 있음)
→ filtered out by MinhashLSH (Jaccard similarity ≥ .95; Pile은 중복 문서가 많음)
→ GPT-2 BPE tokenizer
→ final data : 180B tokens
2022-11
300M
580M
1.2B
3.7B
13B
560M
1.1B
1.7B
3B
7.1B
176B
EleutherAI
BigScience
Model
- 데이터 셋 : ROOTS
◦ 46개 자연어 (multi-lingual) : 한국어 없음
◦ 13개 프로그래밍 언어
- data description, huggingface
- code : megatron-LM & DeepSpeed를 수정하여 활용
. PyTorch (pytorch-1.11 w/ CUDA-11.5; see Github link)
. apex (Github link)
- model : Megatron-LM GPT2 architecture
. Stable Embedding (Layer norm을 wor embeddings layer에 적용; code, paper)
. ALiBI positional encoding (paper)
. GeLU activation functions
. BPE : The BLOOM tokenizer (link) - A simple pre-tokenization rule, no normalization
- training : 2022년 3월 11일 ~ 2022년 7월 5일 (version 1.3)
. 384 A100 80GB GPUs (48 nodes)
. 32 A100 80GB GPUs (4 nodes) in reserve
. 8 GPUs per node using NVLink 4 inter-gpu connects, 4 OmniPath links
. GPU Memory : 640GB per node
. CPU Memory : 512GB per node
. NCCL-communications network
. inter-node connect : Omni-Path Architecture (OPA)
. Disc IO Network : shared network with other types of nodes
. Training throughput : ~150 TFLOP per GPU per second
. epoch : 1 epoch (95000 iterations)
. total tokens : 366B tokens
2022-12
300M (mt5 fine-tuning)
580M (mt5 fine-tuning)
1.2B (mt5 fine-tuning)
3.7B (mt5 fine-tuning)
13B (mt5 fine-tuning)
560M (bloom fine-tuning)
1.1B (bloom fine-tuning)
1.7B (bloom fine-tuning)
3B (bloom fine-tuning)
7.1B (bloom fine-tuning)
176B (bloom fine-tuning)
BigScience
EleutherAI
SFT
Model
- xP3 (multilingual task mixture; cross-lingual & cross-task paper)
- paper, huggingface
. pre-training에서 보지 못한 언어에 대해 adapter를 활용한 language adaptation 후, zero-shot 실험
- BLOOMZ : BLOOM의 multi-task fine-tuned version
. Adapter architecture : (IA)^3 (inner transformer block activation에 element-wise rescaling 하는 것), continued pretraining, bottleneck adapter, BitFit, LoRA, FishMask 등을 실험
. 결론 : BLOOM + MadX (bottleneck adapter) 조합으로 language adaptation 후 zero-shot 했을 때 성능이 제일 좋음
. 결론 : BLOOMZ (fine-tuned) 는 prompting capability를 잃어버려서, adaptation method가 오히려 성능을 낮춤
2022-12
1.3B
3.8B
5.8B
EleutherAI
BigScience
Model
- TUNiB Korean Data (863GB, 원본 1.2TB)
- github, , huggingface, blog
- Eleuther AI에서 공개한 GPT 구조 언어모델 (Multilingual; 특히 한국어용)
- Model
. 5.8B : 172B tokens, 320k steps, 256 A100 GPUs with the GPT-NeoX framework.
2023-01
350M (OPT-350M fine-tuning)
1.3B (OPT-1.3B fine-tuning)
2.7B (ConvoGPT fine-tuning)
6B (ConvoGPT fine-tuning)
PygmalionAI
SFT
Model
- 56MB Dialogue Data (from multiple sources; 일부분은 AI로 생성한 데이터; high-quality roleplaying data)
- docs, github, guideline, video
- CharacterAI의 유저들이 모여서 만든 챗봇 용 모델
- 공개된 모델 크기 : 350M ~ 6B
. 기반 모델 : OPT & ConvoGPT
- 학습 pipeline : ColossalAI
. 350M : 데이터의 7%도 사용하지 않고 수렴해버려서, 273 KB size로 학습 (6GB VRAM single GPU)
. 1.3B : 11.4M tokens over 5440 steps on a single 24GB GPu, 21 hours
. 2.7B : 48.5M tokens over ~5k steps on 4 NVIDIA A40s using DeepSpeed
. 6B : 48.5M tokens over ~5k steps on 4 NVIDIA A40s using DeepSpeed
- Serving : Gradio UI
2023-02
6.7B (1.0T tokens)
13.0B (1.0T tokens)
32.5B (1.4T tokens)
65.2B (1.4T tokens)
MetaAI
SFT
Model
- English CommonCrawl (67%) : CCNet pipeline quality filtering + filtering model 추가 활용
- C4 (15%) : CCNet pipeline
- Github (4.5%) : Apache, BSD, MIT licenses
- Wikipedia (4.5%) : bg, ca, cs, da, de, en, es, fr, hr, hu, it, nl, pl, pt, ro, ru, sl, sr, sv, uk
- Gutenberg and Books3 (4.5%)
- ArXiv (2.5%) : latex files
- Stack Exchange (2%) : High quality QA data
- paper
- Architecture : Pre-Norm, SwiGLU, Rotary PE (GPTNeo & GPT-J에서 쓰이기 시작하면서 LLM에 활용됨)
- Efficient Implementation : attention 계산 (xformer library) & backward (Flashattention for self-att), autograd 대신 backward function 직접 구현 (activations 값 미리 저장), model & sequence parallelism (memory 감소)
- Resource for 65.2B : 380 tokens/seg/GPU on 2048 A100 GPU with 80 GB of RAM & 1.4 tokens 학습시 21일 소요
2023-02-23
CarperAI
RLHF
Training/Inference Pipeline
github code
• NeMo ILQL (link)
• T5 ILQL & PPO
• LLaMa & Alpaca PPO/SFT support
• HF Transformers integration for ILQL
• Data integration
◦ AnthropicAI HH
2023-03
7B
Stanford
SFT
Model
InstructData
- Alpaca Instruct Data (link) : 52K instruction-following demonstrations from GPT-3.5 responses (175 self-instruct seed tasks & augmentation)
- blog, github
- model input size 512
- supervised learning (RLHF 3단계 중 1단계만 적용한 것)
- 학습 비용 : A100 x 8 for 3 hours at the cost of $100, augmented data generation at the cost of $500
- self-instruct 방식으로 데이터 생성 (modified self-instruct)
. instruction 생성은 한번에 20개씩
. 평가단계는 생략 (기존에는 task identification을 통해, input-first or output-first w/ task class를 선택함)
. response 생성은 1 instruction 당 한개씩
2023-03
5.8B (Polyglot-ko fine-tuning)
7B (LLAMA fine-tuning)
13B (LLAMA LoRA)
30B (LLAMA LoRA)
65B (LLAMA LoRA)
Seoul National Univ.
SFT
Model
InstructData
- Koalpaca Instruct Data
. Alpaca data 중 input만 한국어로 번역
. GPT 3.5 (ChatGPT) 로 한국어 답변 생성 (self-instruct 방식)
. n=10으로 생성하는 것이 가장 안정적
- github
- finetuning base models : LLAMA LoRA (13B, 30B, 65B), Polyglot-ko fine-tuning (5.8B), LLAMA fine-tuning (7B)
- Alpaca와 동일한 modified self-instruct
2023-03
6B (GPT-J Fine-tuning)
Databricks
SFT
Model
- alpaca dataset (link) : text-davinci-003으로 생성한 52,000개 instructions and demonstrations dataset
- blog
- HuggingFace model card (dolly-v1-6b) : https://huggingface.co/databricks/dolly-v1-6b
- Databricks ML Platform & Deepspeed ZeRO 3
- 초기 version : 1 epoch 학습 in 30 mins
- dolly-v1-6b : 10 epochs 학습
2023-03
13B (LLaMA fine-tuning)
UC Berkeley
CMU
Stanford
UC San Diego
SFT
Model
InstructData
- ShareGPT : 53k cleaned English data obtained by ChatGPT (from ~100k original data) → 실제 학습에는 70k 데이터 활용했다고 함.
. multi-turn
. 데이터 전처리 : HTML → Markdown / filter out low-quality samples / divide lengthy conversations into smaller segments that fit the model’s maximum context length
- blog, github, demo, huggingface(GPTQ 4bit), Data & Cleansing & Finetuning
. data link : ShareGPT (chatgpt 대화 내용 공유를 extension을 통해 진행; website, data), alpaca instruct data, shareGPT filtered data
- Model (학습 코드는 alpaca를 수정해서 진행)
. input size 2048
. CPU 60GB RAM, GPU 28GB VRAM 이상에서 작동 (하지만, 3090으로 작동 확인)
. 체크포인트는 LLaMA 13B 체크포인트에 delta weight를 더해서 업데이트 하는 방식으로 제공
. 체크포인트는 huggingface transformers로 작동
. Finetuning은 pytorch FSDP & A100 8개로 하루동안 진행, Skypilot(링크)이라는 것을 이용하여 학습 비용은 $1000 -> $300으로 최적화
. gradient checkpointing & flash attention
- Tools
. 학습 : SkyPilot (managed spot jobs)
. Serving : FastChat (gradio)
. Evaluation : GPT-4
- comparison : https://vicuna.lmsys.org/eval/
. GPT-4를 이용한 평가에서, ChatGPT ~ Bard > Vicuna > Alpaca > LLaMA
2023-03
RLHF
InstructData
- kochatgpt data (link)
1. 아래의 4가지 데이터에서 질문셋 167,577 수집 → 12000개 질문 랜덤 선택
. ChatbotData : 11824 문장
. AI허브_한국어 대화 : 49711 문장
. AI허브_일반상식 : 100268 문장
. KorQuad : 5774 문장
2. ChatGPT를 이용한 답변 생성
3. ChatGPT를 이용하여, 대화 데이터 생성 (ChatGPT가 사람vs.챗봇 대화를 둘 모두 만들도록 함)
4. RM을 위한 Ranking 데이터 : 10220개
. 동일한 prompt에 대해 “ChatGPT, GPT3.5 davinci-003, GPT3 ada-001” 생성
. ChatGPT > GPT3.5-davinci > GPT3-ada 순으로 ranking 자동 레이블링
. RM 모델 학습을 위한 데이터는 이중 두개씩을 묶어서, chosen & rejected 로 만듦
5. PPO dataset : 초기 12000개의 질문만을 활용.
2023-03-10
LAION-AI
InstructData
[OIG dataset] : link
~43M instructions으로 구성되는 대부분 synthetic data로 이루어진 대규모의 데이터
• OIG-small-chip2 (200K) - Done and released. See small_instruction_set sub-directory.
• OIG-40M - Done - Done and released. See 40M sub-directory
• OIG-100M - In progress, to be released expected April 30, 2023
2023-03-29
7B (LLaMa RLHF)
HPC-AI tech
RLHF
SFT
Training/Inference Pipeline
InstructData
- InstructWild (link): 52k instructions for English (24M tokens) & 52K instructions for Chinese (30M tokens)
. 생성 과정 : 700 noisy instructions 수집 from Twitter & filter out noisy ones → 429 clean instruction (alpaca와 다르게 제한없이 instruction 얻음) → ChatGPT → 5개의 prompts를 예시로 두고 새로운 instruction들을 생성하도록 함 → ChatGPT → 각각의 instruction에 대해 response 수집
. 영어와 중국어 각각 별도로 수집
. 데이터 모으는데 총 $880 소모
- Homepage, blog, ColossalAI Github, ColossalChat github
- 거대 GPT 모델 학습을 위한 pipeline 제공
- 10x speedup, 47x cost savings, 175B 이상의 parameters
- the first to open-source a complete RLHF pipeline : from training to deployment
- 학습/추론 pipeline 제공 : Pytorch 대비 추론 1.4배, 학습 7.7배, 10.3배 큰 모델 학습 가능 (alpaca code 대비 학습 속도 3배 빠름)
- automatic parallelism, memory management, dynamic scheduling, “data / pipeline / sequence / tensor parallelism”
- chip and cloud agnostic : GPUs, TPUs, FPGAs, CPUs
- ColossalAI Talking Intelligence (Coati models) : RLHF Pipeline 제공
• Supports comprehensive large-model training acceleration capabilities for ColossalAI, without requiring knowledge of complex distributed training algorithms
• Supervised datasets collection
• Supervised instructions fine-tuning
• Training reward model
• Reinforcement learning with human feedback
• Quantization inference
• Fast model deploying
• Perfectly integrated with the Hugging Face ecosystem, a high degree of model customization
- Limitations of LLaMA-finetuned models and dataset
. limitation of LLaMa fine-tuning models : missing knowledge by LLaMa / Lack of counting ability / Lack of Logics (reasoning and calculation) / Tend to repeat the last sentence / poor multilingual results
. limitation of InstructWild dataset : Lack of summarization ability / multi-turn chat and role-playing / self-recognition / Safety
- Quantization 지원 & Deployment 지원
. 8-bit quantization (RTN), 4-bit quantization (GPTQ), and FP16 inference.
2023-04-03
13B
UC Berkeley
SFT
InstructData
Model
Training/Inference Pipeline
[ChatGPT DIstillation Data]
- ShareGPT : 30k cleaned English data obtained by ChatGPT (from ~60k original data)
. multi-turn
- HC3 (paper) : 24k questions 에 대해 사라므이 대답 60k & ChatGPT 대답 27k (총 87k QA examples)
. single-turn
[Open Source Data]
- OIG : Open Instruction Generalist , LAION에 의해 만들어진 “garde-school-math-instructions, poetry-to-songs, plot-screenplay-books-dialogue” 30k examples
. single-turn
- Alpaca dataset (link)
. single-turn
- Anthropic HH : ~160k Human-rated examples (harmfulness & helpfulness 기준, response pair 중에 더 선호되는 것)
- OpenAI WebGPT : ~20K comparisons (a question, a pair of model answers, and metadata, comparision human rates with a preference score)
- OpenAI Summarization : ~93K examples
. comparison part : 2개의 summaries 중 best를 고르는 것
. axis part : likert scale로 quality 평가하는 것 (overall, accuracy, coverage, coherence, compatible)
[test set]
- testset (link) : 180 queries (자체 데이터 + Alpaca testset)
- homepage, demo
- github code
- 웹에서 얻은 대화 데이터를 기반으로 LLaMA를 fine-tuning 한 모델
- JAX/Flax를 활용한 EasyLM을 활용하여, pre-train, fine-tune, serve, evaluate 진행
- Training : 8 A100 GPUs (a single Nvidia DGX) & 6 hours for 2 epochs & <$100
- evaluation : Alpaca보다 좋고, 반정도의 데이터에서 ChatGPT와 비슷한 성능
- result : ChatGPT > Koala ~ Alpaca
. testset (link) : 180 queries & human evaluation
- comparison data를 학습시에는, “a helpful answer” for positive, “an unhelpful answer” for negative를 conditioning 한 뒤 정답 생성.
. human feedback이 없는 데이터는 “a helpful answer”를 붙임.
. evaluation 시에도 “a helpful answer” 붙임.
2023-04-06
LAION-AI
InstructData
[oasst1]
• New Data : human-generated, human-annotated assistant-style conversation corpus 161,443
◦ 66,497 conversation trees
◦ 35개의 서로 다른 언어
◦ 461,292 quality ratings
◦ 13,500 volunteers
• Ready for export : Spam & Deleted data 제외 (초기 prompt로만 구성 : prompt_lottery_waiting; 낮은 퀄리티 : aborted_low_grade; 중단 : halted_by_moderator)
◦ 10,364 conversation trees
◦ 88,838 messages
paper, code, New Data, blog, website for chat, roadmap, Data Structures, models
• 2022년 12월 Project launch
• 2023년 4월 6일, Models & Training Data & Code 공개
Other data 참고
• oasst-mix : sft를 위한 추가 데이터
◦ vicuna (non-commercial)
◦ code_alpaca (non-commercial)
◦ dolly15k (commercial)
◦ grade_school_math_instructions
• RM Data : rm 학습을 위한 추가 데이터
◦ Anthropic HH : ~160k Human-rated examples (harmfulness & helpfulness 기준, response pair 중에 더 선호되는 것)
◦ SHP : ~385K Stanford Human Preferences dataset
◦ hellaswag
◦ webgpt
◦ hf_summary_pairs
• RM Others
◦ summarize_from_feedback
◦ synthetic-instruct-gptj-pairwise
2023-04-12
12B (pythia-12b Fine-tuning)
Databricks
SFT
Model
InstructData
- dolly15k : Instruction/response fine-tuning 15k Data for the first instruction-following LLM
- 기존 instruction following 모델인 Alpaca, Koala, GPT5All, Vicuna 모두 ChatGPT 결과로부터 만들어진 데이터를 활용했기에 상업적 활용이 불가했음. 상업적 활용이 가능하도록 새롭게 데이터를 만들었고, 이를 통해 학습된 모델 & 코드 & 데이터 공개함.
- blog
- HuggingFace model card (dolly-v2-12b) : https://huggingface.co/databricks/dolly-v2-12b
- training model : pythia-12b model family
- Data description and download
. InstructGPT의 가이드를 따라서 7개의 기존 category에 하나(open-ended free form)를 추가하여, 총 8개의 prompt / response pair를 만듦
. 5000명 이상의 Databricks 직원들이 InstructGPT의 방식으로 데이터를 생성함
. Tasks : brainstorming, classification, closed QA, creative writing, information extraction, open QA, and summarization.
. Wikipedia 소스를 제외한 나머지 웹 소스는 활용하지 않도록 함
. generative AI의 결과를 이용하지 않도록 함
. 전체 데이터 작업 중에, 반은 질문을 생성하도록 하고, 나머지 반은 본래 질문을 rephrase + response를 만들도록 함.
. 별도의 context 필드에는 활용된 reference wikipedia의 내용이 포함되어 있고, 이들은 citation number [42] 가 포함되어 있어서, downstream application에서는 이를 제거할 것을 추천함.
- 활용법 : instructions examples을 생성하기 위한 few-shot examples & data augmentation (restate & translate)
2023-04-12
Microsoft
RLHF
Training/Inference Pipeline
- DeepSpeed Chat: Easy, Fast and Affordable RLHF Training of ChatGPT-like Models at All Scales
. Doc, code example
- Features
. Easy-Breezy Training & Inference API : A complete E2E RLHF training (from Huggingface model + an inference API)
. High performance system : Hybrid Engine achieves 15x training speedup over SOTA RLHF systems (memory management & data movement across different phases of RLHF)
. Accessible Large Model Support : a single or multi-GPUs through ZeRO and LoRA
. An Universal Acceleration Backend for RLHF : Support InstructGPT pipeline (+ data abstraction & blending capabilities for multiple data sources)
- Hybrid Engine for Optimization
• Inference : a light-weight memory management system (KV-cache & intermediate results)
◦ highly-optimized inference-adapted kernels
◦ tensor parallelism implementation (model partitioning)
• Training : memory optimization techniques
◦ ZeRO family (sharding) (model partitioning) & LoRA
- Performance
. OPT-13B (9 hours; $300 Azure cloud) & OPT-30B (18 hours; $600 Azure cloud)
. 13B (1.25 hours; 64 GPU cluster) & 175B (1 day; 64 GPU cluster)
[training speed; throughput]
. single GPU : 10x for RLHF
. multiple GPUs : 6-19x speedup over Colossal-AI & 1.4-10.5x over HuggingFace DDP
. example
. Actor (OPT-66B) & Reward (OPT-350M) : Step1 (82m) - Step2 (5m) - Step3 (7.5h)
. Actor (OPT-1.3B) & Reward (OPT-350M) : Step1 (2900s) - Step2 (670s) - Step (1.2h)
[model scalability]
. DeepSpeed-HE : 6.5B (a single GPU) & 50B (a single A100 40G node)
. Colossal-AI : 1.3B (a single GPU) & 6.7B (a single A100 40G node)
2023-04-20
3B
7B
Stability AI
SFT
Model
The Pile
Alpaca
GPT4All (400k) : GPT-3.5 Turbo로 생성한 437,605개의 (prompts-responses) dataset
Anthropic HH : ~160k Human-rated examples (harmfulness & helpfulness 기준, response pair 중에 더 선호되는 것)
DataBricks Dolly
ShareGPT
code
• StableLM-alpha (2023-04-20)
◦ 3B & 7B (이후에 15B & 65B release 예정)
◦ Data
The Pile
◦ CC BY-SA-4.0 : Commercial
• StableLM-tuned-alpha
◦ 3B & 7B
◦ StableLM-alpha의 추가 SFT version
◦ Data
Alpaca (52k)
GPT4All (400k) : GPT-3.5 Turbo로 생성한 437,605개의 (prompts-responses) dataset
Anthropic HH : ~160k Human-rated examples (harmfulness & helpfulness 기준, response pair 중에 더 선호되는 것)
DataBricks Dolly (15k)
ShareGPT English Subset
◦ StableLM-alpha →SFT
◦ CC BY-NC-SA-4.0 : Non-commercial
The Pile
◦ CC BY-SA-4.0 : Commercial
• StableLM-tuned-alpha
◦ 3B & 7B
◦ StableLM-alpha의 추가 SFT version
◦ Data
Alpaca (52k)
GPT4All (400k) : GPT-3.5 Turbo로 생성한 437,605개의 (prompts-responses) dataset
Anthropic HH : ~160k Human-rated examples (harmfulness & helpfulness 기준, response pair 중에 더 선호되는 것)
DataBricks Dolly (15k)
ShareGPT English Subset
◦ StableLM-alpha →SFT
◦ CC BY-NC-SA-4.0 : Non-commercial2023-04-28
13B
Stability AI
RLHF
Model
[Training Data]
oasst1
GPT4All (400k) : GPT-3.5 Turbo로 생성한 437,605개의 (prompts-responses) dataset
Alpaca
[Data for RM]
oasst1
Anthropic HH : ~160k Human-rated examples (harmfulness & helpfulness 기준, response pair 중에 더 선호되는 것)
SHP : ~385K Stanford Human Preferences dataset (348,718 datasets. 요리에서 철학에 이르는 서로 다른 18개 영역에 대한 questions/instructions datasets)
[Stability AI releases StableVicuna, the AI World’s First Open Source RLHF LLM Chatbot]
code
• StableVicuna-13B (2023-04-28)
◦ LLaMA-13B →SFT Vicuna-13B v0 →RLHF
◦ Training data
oasst1
GPT4All (400k) : GPT-3.5 Turbo로 생성한 437,605개의 (prompts-responses) dataset
Alpaca (52k)
◦ Data for RM
oasst1
Anthropic HH : ~160k Human-rated examples (harmfulness & helpfulness 기준, response pair 중에 더 선호되는 것)
SHP : ~385K Stanford Human Preferences dataset (348,718 datasets. 요리에서 철학에 이르는 서로 다른 18개 영역에 대한 questions/instructions datasets)
◦ CC BY-NC-SA-4.0 : Non-commercial
oasst1
GPT4All (400k) : GPT-3.5 Turbo로 생성한 437,605개의 (prompts-responses) dataset
Alpaca (52k)
◦ Data for RM
oasst1
Anthropic HH : ~160k Human-rated examples (harmfulness & helpfulness 기준, response pair 중에 더 선호되는 것)
SHP : ~385K Stanford Human Preferences dataset (348,718 datasets. 요리에서 철학에 이르는 서로 다른 18개 영역에 대한 questions/instructions datasets)
◦ CC BY-NC-SA-4.0 : Non-commercial2023-05-03
6.9B (Pythia)
12B (Pythia)
20B (GPT-NeoX)
H2O
SFT
Model
oasst1
OIG
code, web demo, blog
• code
◦ LoRA & 8-bit quantization 제공
◦ chatbot server code via GPU & Python client API
◦ evaluation code
• model list
◦ oasst1-512-20b : gpt-neox-20b로부터 openassistant data (oasst1-46283 & oasst1-48307)로 SFT 모델
◦ oasst1-512-12b : pythia-12b로부터 openassistant data (oasst1-46283 & oasst1-48307)로 SFT 모델
◦ oig-oasst1-512-6.9b : pythia-6.9b로부터 oig & oasst1 data & oasst1-48307로 SFT 모델
◦ oig-oasst1-256-20b : gpt-neox-20b로부터 oig & oasst1 data 로 SFT 모델
◦ oig-oasst1-256-12b : pythia-12b-deduped로부터 oig & oasst1 data 로 SFT 모델
2023-11
7B
13B
Microsoft
SFT
Model
tailored, high-quality synthetic data generated by GPT4
• intuition : small capa에서는 large capa에서의 생성 전략이 best가 아닐 수 있음. GPT-4가 direct answer를 내지만, smaller model은 더 작은 task 단위로 나눠서 답변을 생성해야함.
• how-to : very detailed instructions and even multiple calls
2024-02
13B
Cohere
RLHF
SFT
Model
InstructData
• xP3x
• Aya Dataset
• Aya Collection
• DataProvenance collection
• ShareGPT-Command
3. Training & Inference Pipeline (RLHF)
TRLX (20230223)
ColossalChat (202303)
DeepSpeed-Chat (20230412)
4. Commercially Open-sourced Model/Data/Code
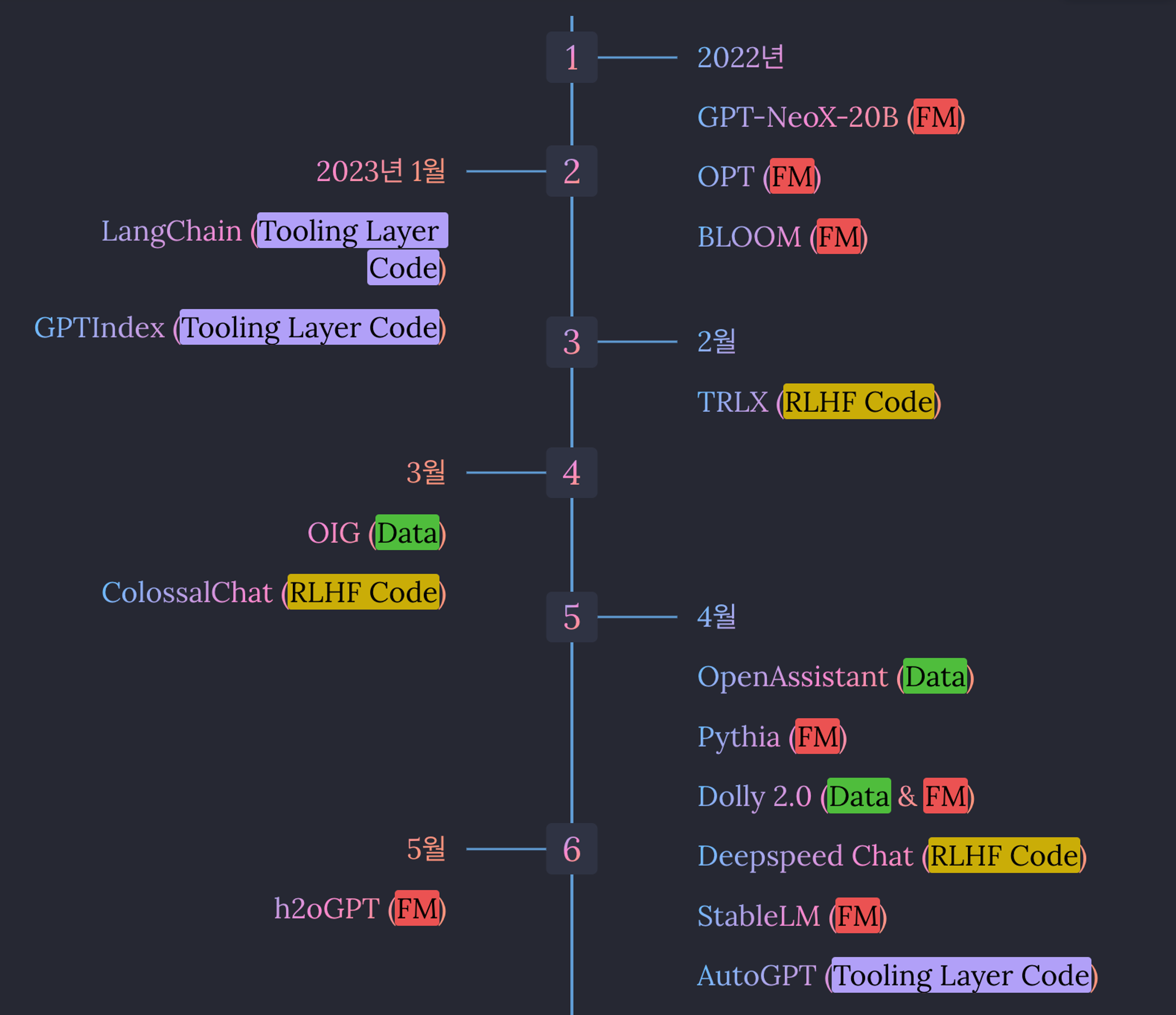
5. Tooling Layer Open-source Codes
•
6. Open-source List (Not yet analyzed; to-be)
•
OpenChatKit : Commercial (Create specialized and general purpose chatbots)
•
Cerebras-GPT (from 111M to 13B) : Commercial (GPT-3 family)
•
Flan-UL2 : Commercial (Google’s T5 family)
•
GeoV (9B) : Commercial (RoPER; Rotary Positional Embeddings with Relative distances)
•
Dalai : Non-commercial (The simplest way to run LLaMA on your local machine)
•
Baize (from 7B to 30B) : Non-commercial (trained with LoRA using 100k dialogs)
•