

•
George Hotz가 podcast에서 언급한 GPT-4 Architecture에 대한 내용에 대해 작성한 문서이며, GPT-4 Architecture로 언급된 Mixture-of-Experts에 대한 설명과 최근 Trends인 Sparse Mixture-of-Experts에 대한 내용을 정리한 문서
•
Reference
◦
Soumith Chintala & Michael Benesty : tweets
◦
Matt Reckard Blog : Mixture of Experts: Is GPT-4 Just Eight Smaller Models?
◦
WandB news : AI Expert Speculates on GPT-4 Architecture
GPT-4 Conjecture
•
초창기 GPT-4가 공개되었을 때, 사람들은 1T parameters & GPT-3보다 6배 더 큰 크기로 사람들은 생각하고 있었음
•
2023년 6월 20일, 아이폰 & 소니 PS3의 첫번째 해커이자, 자율주행 회사 Comma.ai 의 공동창업자 George Hotz가 podcast에서 GPT-4 size/architecture을 언급
[Transcription]

[영상 관련 Tweet]
The Mentioned GPT-4 Size & Architecture
[1.2T MoE; Mixture of Expert] 8개의 MoE 220B experts 모델로 구성되어 있는 총 1.2T 모델
•
최근 MS와 Google에서 활발하게 연구된 Sparse MoE 혹은 전통적인 Ensemble MoE 등 다양한 방식 중에 구체적으로 어떤 방식인지는 언급하지 않음.
[16-iter inference] 한번의 결과를 추출하기 위해, 16번의 반복적인 inference 과정을 거치면서 결과를 수정해나가는 과정
•
구체적으로 어떤 방식으로 16번의 반복 생성 과정을 거치는지는 언급되지 않음
◦
iterative semi-autoregressive 방식에서 활용하듯이, 단일 chunk 별 반복적인 revising?
◦
전체 output에 대한 반복적인 revising?
다양한 Reactions
아래 tweet thread를 보면 다양하고 재미있는 내용들이 많음.
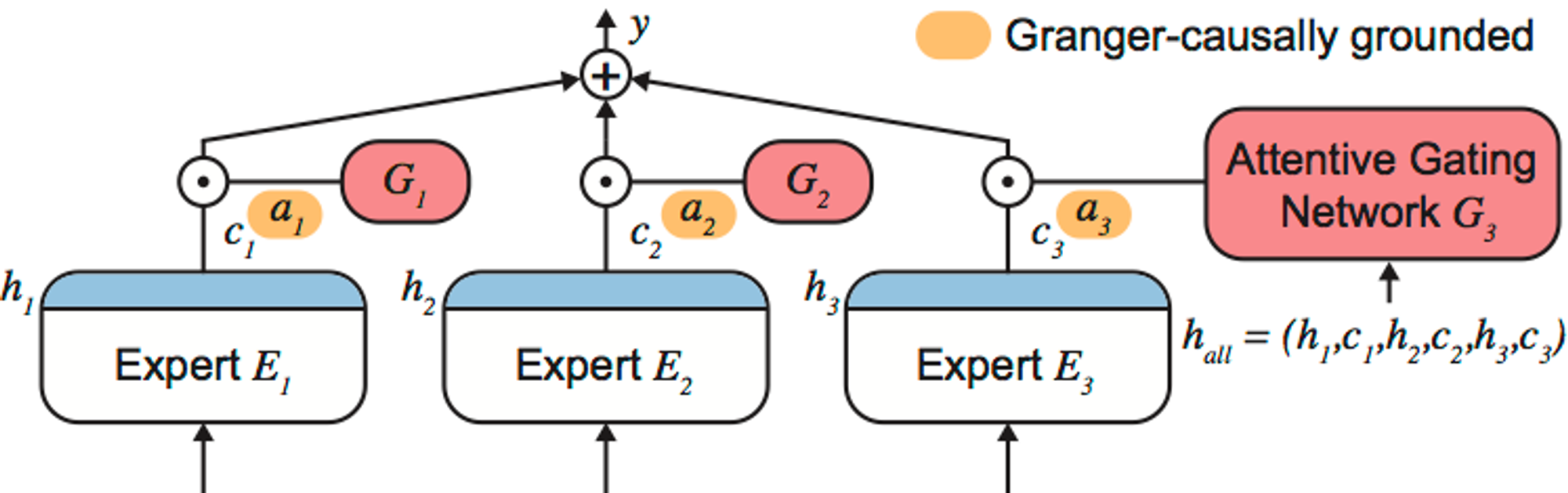
MoE(Mixture of Experts)란?
MoE 방식은 여러 개의 AI 모델들을 다양한 방식으로 학습한 뒤, 각 모델의 결과를 합쳐 하나의 결과로 제안하는 전통적인 앙상블 (Ensemble) 기계 학습 (Machine Learning) 기법을 의미함.
Source: https://github.com/d909b/ame
•
각각의 AI 모델을 Expert로 취급하여 이들을 묶어서 구조를 만들고 이들을 통한 집단 지성(collective intelligence)을 결과로 활용하기에 Mixture of Experts라고 부름
•
일반적으로 하나의 AI 모델이 주어진 데이터와 계산 자원 내에서 한계치에 도달했을 때, 성능을 조금이라도 높이려는 목적으로 이용되며, 주로 대회(Competition)용 구조로 이용이 되어 AI Competition Platform인 Kaggle의 이름을 따서 Kaggle-style MoE라고도 부름
실제로 거의 모든 Kaggle competition 우승은 ensemble 모델이 차지함. 즉, 보통 마지막까지 성능을 어떻게든 짜내는 방법으로 MoE 방식을 활용하게 됨.
장점
•
적응성(Adaptability) & 해석가능함(Interpretability) : 각 Expert들은 세부적인 sub-task나 특정 데이터 도메인을 담당하도록 하여 모델의 관리/테스트를 좀 더 수월하게 하거나, 각 목적에 따라 손쉽게 적응하도록 만들고, 이에 따라 모델 결과에 대한 이해도를 높일 수 있음
•
확장성(Scalability) : 다양한 필요 조건에 따라, Expert를 추가나 삭제하는 것으로 손쉽게 크기에 대한 변경 가능
단점
•
복잡도(Complexity) : “수많은 모델을 개발/배포/유지를 해야하는 것” & “run-time inference 계산 시간이 매우 늘어나는 점” 때문에 실제 production-level에서 쓰이기에는 유효하지 않은 경우가 많음
•
학습 부담(Training Overhead) : 여러 Experts를 학습해야하기에 학습 부담이 증가하여 학습 자원 및 시간이 오래 걸림
고려 사항
•
Expert 모델 구조 (Model Architecture) : 서로 다른 기계 학습 모델을 활용하거나, 모두 동일한 모델도 활용 가능함
•
데이터 분할 (Data Partitioning) : 모든 Expert를 동일한 데이터로부터 학습을 시킬 수도 있지만, 각 Expert에 전문 분야를 할당하여 학습시킬 수 있음
•
Expert 조합 방식 (Expert Combining) : 최종 결과를 생성하기 위해 각 Expert의 결과를 어떤 방식으로 합칠지 결정해야함. 대표적으로는 weighted averaging / gating mechanisms / a seperate model to combine 이 존재함
•
학습 방식 (Training Method)
◦
Task : 모든 Expert를 동일한 task에 대해 학습시킬 수도 있지만, 각각 다른 task에 대해 학습시킬 수도 있음
◦
Optimization Process : 아래와 같은 예시들처럼 다양한 과정으로 나눠서 학습이 가능함
▪
Generalist : 하나의 Expert를 먼저 학습 시킨 뒤, 이를 전체 Experts의 초기값으로 활용하여 MoE 전체를 학습
▪
Specialist : 각각의 데이터/Task에 따라 Expert들을 별도로 학습시킨 뒤, 이들을 초기값으로 활용하여 MoE 전체를 학습
▪
Two-step approach : 각각의 데이터/Task에 따라 Expert들을 별도로 학습시킨 뒤, Expert 조합하는 방식만 추가로 학습
Recent MoE Trends - SMoE
최근 연구 내용은 Sparse MoE (SMoE) 에 집중되어 있으며, Routing mechanism을 이용한 architecture가 주된 방식이다.
2nd Big Wave of Deep Learning Architecture in MS & Google
MS와 Google은 SMoE architecture가 Transformer에 이은 2nd Big Wave라고 생각할 정도로 다양한 방식으로 이러한 architecture를 적용해왔음.
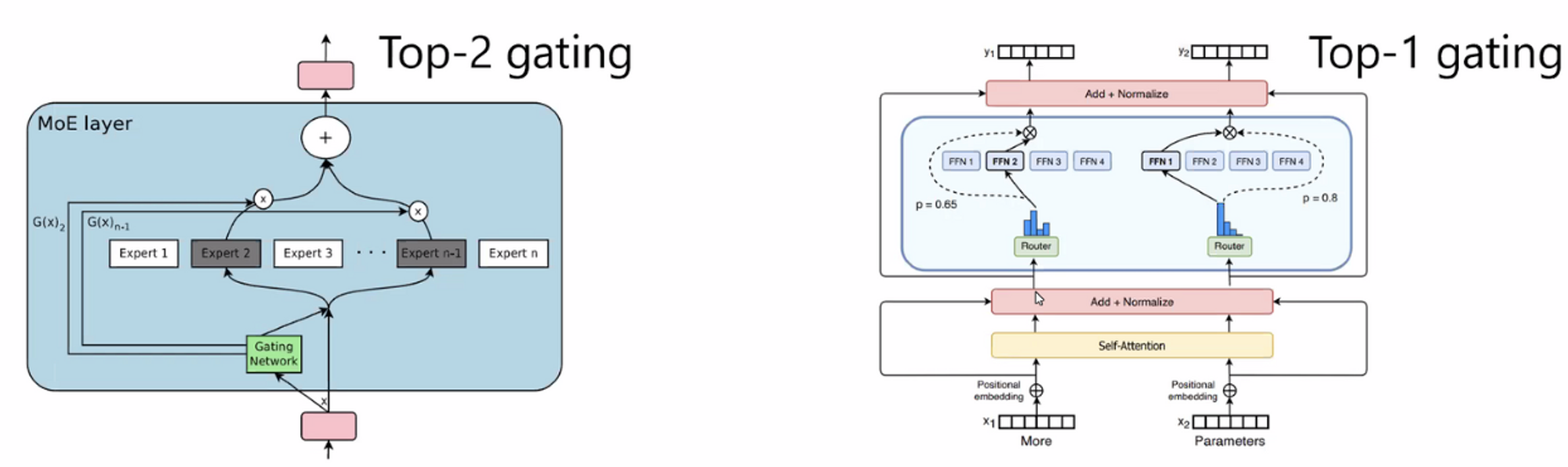
2021, Google, Switch Transformer (Switch Routing 방식; Total Model Size 1.6T; MoE active Model Size 1.5B)
•
Switch Routing: sparse FFN을 위해 model parallelism을 활용해 여러 작은 FFN layer 중에 token별로 하나의 FFN layer를 선택해서 학습하도록 함
◦
하나를 선택하기 위한 gating layer : linear layer w/o bias → softmax → 값이 높은 쪽 expert를 활용
2021, Google, GLaM (Total Model Size 1.2T; MoE active Model Size 96.6B)
•
Generalist MoE architecture (Top2-gating) 활용
•
모델 사이즈는 GPT-3보다 7배 크지만, 학습 cost는 1/3이고, inference 용 Compute FLOPs은 1/2임
SMoE 모델의 장점
•
입력에 대해, 전체 parameter 중에 일부분만 활용하기에 sparse 특징을 띔
•
expert parallelism 은 model parallelism 보다 훨씬 적은 computation을 필요로 하게 됨
•
결과적으로 inference computation cost가 매우 줄어들게 되며, 항상 동일한 computation만 필요함 (Top-1 gating; Top-n gating의 경우 sub-linear 계산량)
SMoE 학습이 어려운 이유
•
Experts 개수를 정하는 문제 : 보통은 GPU memory / GPU 개수 / 전체 resource budge에 따라 설정
•
Expert 학습 방식은 Specialist or Generalist? : 각 Expert 마다 특정 데이터/Task에 특화된 형태로 학습할 것인가? 모든 Expert를 전체 데이터로 학습할 것인가?
◦
Generalist : 하나의 Expert에 해당하는 base model 하나를 먼저 학습시킨 뒤, 이를 전체 MoE 초기 params으로 활용
◦
Specialist : 각각의 데이터/Task에 따라 Expert들을 별도로 학습시킨 뒤, 이들을 MoE 초기 params으로 활용
•
MoE의 효율적인 학습을 위해서는 여러 parallelism 학습 방식을 결합시킨 형태가 필요함
◦
Efficient Training Methods for Routing : Routing 시에 random으로 할당되기 때문에, 이에 대한 control 및 parallelism 방식이 필요
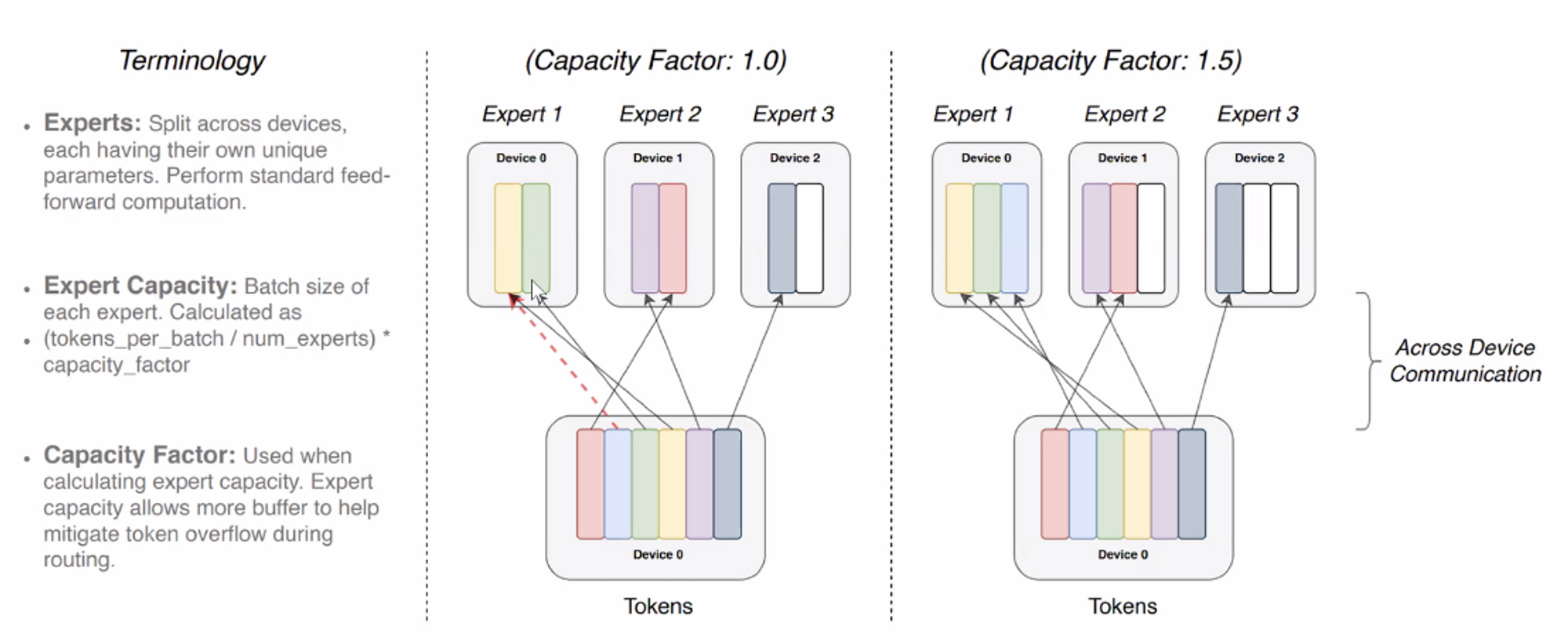
◦
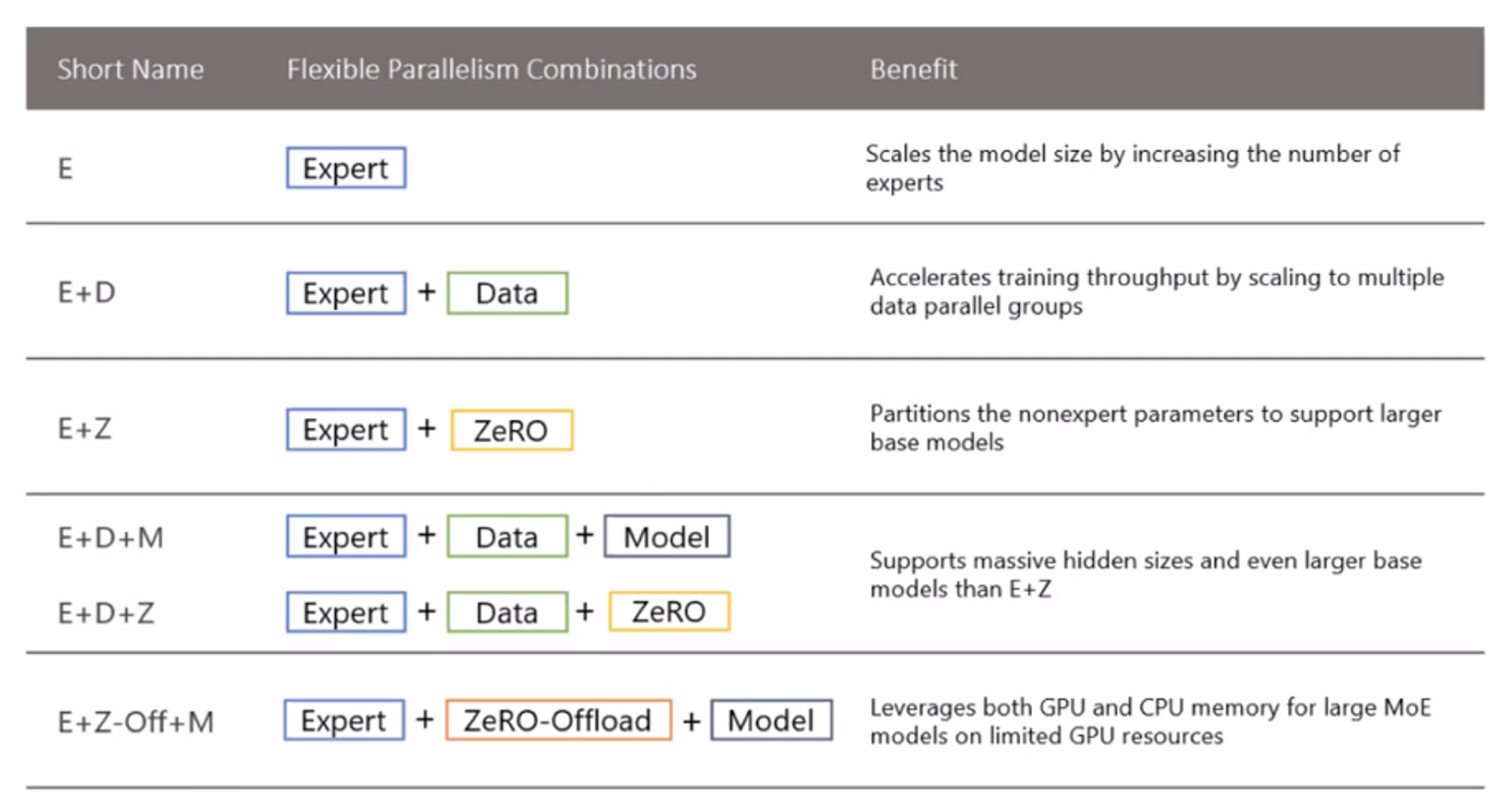
SMoE를 위한 여러 Techniques (Balancing loss, RTS, AoE, Pruning, Stocahstic Expert, Sinkhorn Redistribution)
•
Balancing loss on Experts : 몇개의 expert만 학습되는 것을 방지하기 위해 CE loss 계산 시 balancing loss 추가 → gradient가 한쪽 expert로만 치우치는 것을 막음
•
RTS (Random Token Selection) : Switch의 경우 앞쪽 token에 먼저 expert 할당권한(학습시 selection bias 생성)을 주었는데, 모든 token 마다 동일하게 expert 할당 권한을 부여
•
AoE (Aggregation of Experts) : 학습시 소규모의 expert들로 학습을 한 뒤, 전체 expert들에 대해 확장 (transfer)
•
Pruning : 학습시에는 대규모의 expert들을 학습한 뒤, inference (deployment) 시에는 eval에서 가장많이 활용된 top-K만 활용
•
Stochastic Expert : gating을 없애고 random으로 expert 하나를 선택하되, 매 학습마다 두개의 forward를 얻어서 softmax output에 KL-divergence loss를 추가 → 모든 expert들을 generalist로 만들되, 이러한 generalist를 여러개 두는 효과
•
Sinkhorn Redistribution : gating layer의 logit으로부터 expert를 softmax로 선택하기 보다는, 수학적으로 “하나의 token input은 하나의 expert를 선택하도록 한다” (gating layer의 entropy 상승) & “각각의 expert는 전체 tokens 중 할당받는 비율이 같도록 한다” (balancing constraints) 를 반영한 문제를 정의하고, 이를 풀 수 있는 솔루션을 활용
2022, Google, Unified Scaling Laws for Routed Language Models
SMoE 모델에 대한 Scaling Laws
2022, Google, Unified Scaling Laws for Routed Language Models
•
S-BASE, HASH, RL-R 3가지 MoE 학습 방식에 대해, “model size ” & “experts 수 ”에 따른 MoE loss scaling law에 대한 분석 (각각의 factor가 커짐에 따라서 얼마나 효율적으로 loss가 줄어드는가?)
showing that the scaling with number of experts diminishes as the model size
increases → 즉, 제안된 방법론들에 대해서는 큰 모델일수록 MoE의 효율이 줄어든다.
기본 모델의 사이즈가 1.3B 이하인 경우, MoE의 효율이 매우 높음 → e.g. “ & ” ~ “ & ”
“model size ” & “experts 수 ”는 scaling behavior에 영향을 많이 주지만, “data 마다 선택되는 expert 수 ” & “Routing layer의 비율 ” 은 크게 영향을 주지 않는다.
1.
Sinkhorn Redistribution을 활용하는 S-BASE가 가장 효율적 (모델이 커짐에 따라 loss가 더 효율적으로 감소하며, 안정적임
2.
새로운 알고리즘에 대해 다양한 “model size” & “experts 수” 에 대해 검증이 필요함 (하나의 case에 대한 실험으로는 다른 case에 대해 검증될 수 없음)
3.
추천 setting : 64/128 experts & K=1 expert