Intro
A family of lightweight, state-of-the art open models (Commercial) built from the same research and technology used to create the Gemini models

References
•
Main Page : https://ai.google.dev/gemma?hl=en
•
HuggingFace (2B, 7B; pre-trained model, instruction-finetuned model; 16bit, 8bit, 4bit)
◦
demo : https://huggingface.co/chat
•
Official Guideline
◦
Pytorch (via kagglehub; 2B & 7B) : https://ai.google.dev/gemma/docs/pytorch_gemma
◦
LoRA fine-tuning : https://ai.google.dev/gemma/docs/lora_tuning
◦
•
Kaggle Notebook example : https://www.kaggle.com/models/google/gemma/code/
◦
Finetuning & Inference : https://www.kaggle.com/code/nilaychauhan/keras-gemma-distributed-finetuning-and-inference
Released Models
•
Size : 2B, 7B
•
Training Type : pre-trained model, instruction-finetuned mode (its own prompt style)
•
Different Precisions : 16bit, 8bit, 4bit
License
Training Data
•
Totaling 2T/6T Tokens for 2B/7B
•
Data Types
1.
Web Documents: A diverse collection of web text ensures the model is exposed to a broad range of linguistic styles, topics, and vocabulary. Primarily English-language content.
2.
Code: Exposing the model to code helps it to learn the syntax and patterns of programming languages, which improves its ability to generate code or understand code-related questions.
3.
Mathematics: Training on mathematical text helps the model learn logical reasoning, symbolic representation, and to address mathematical queries.
•
Data Preprocessing
◦
CSAM Filtering: Rigorous CSAM (Child Sexual Abuse Material) filtering was applied at multiple stages in the data preparation process to ensure the exclusion of harmful and illegal content.
◦
Sensitive Data Filtering: As part of making Gemma pre-trained models safe and reliable, automated techniques were used to filter out certain personal information and other sensitive data from training sets.
◦
Performance
•
Open LLM Leaderboard
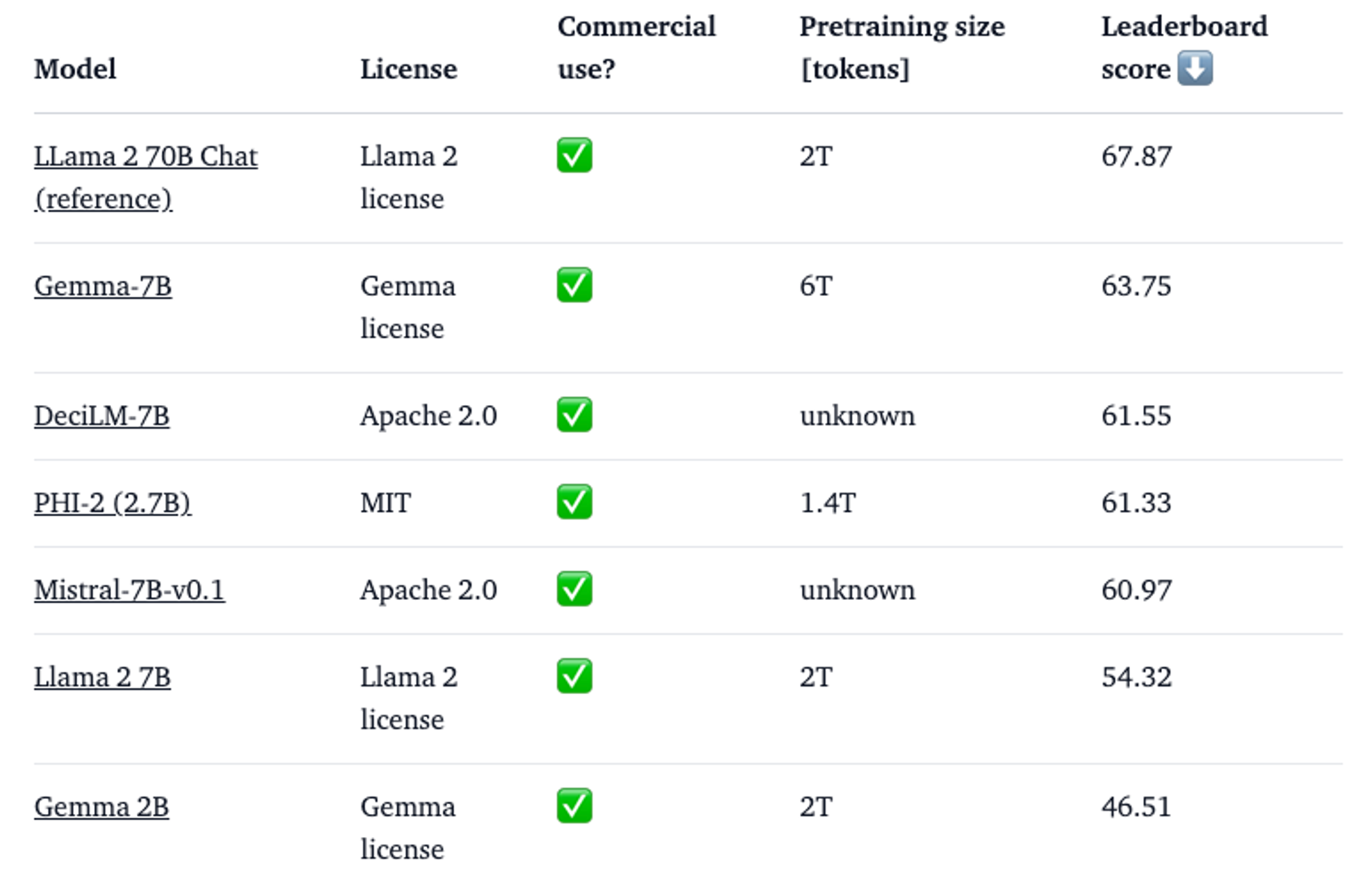
•
Comparison
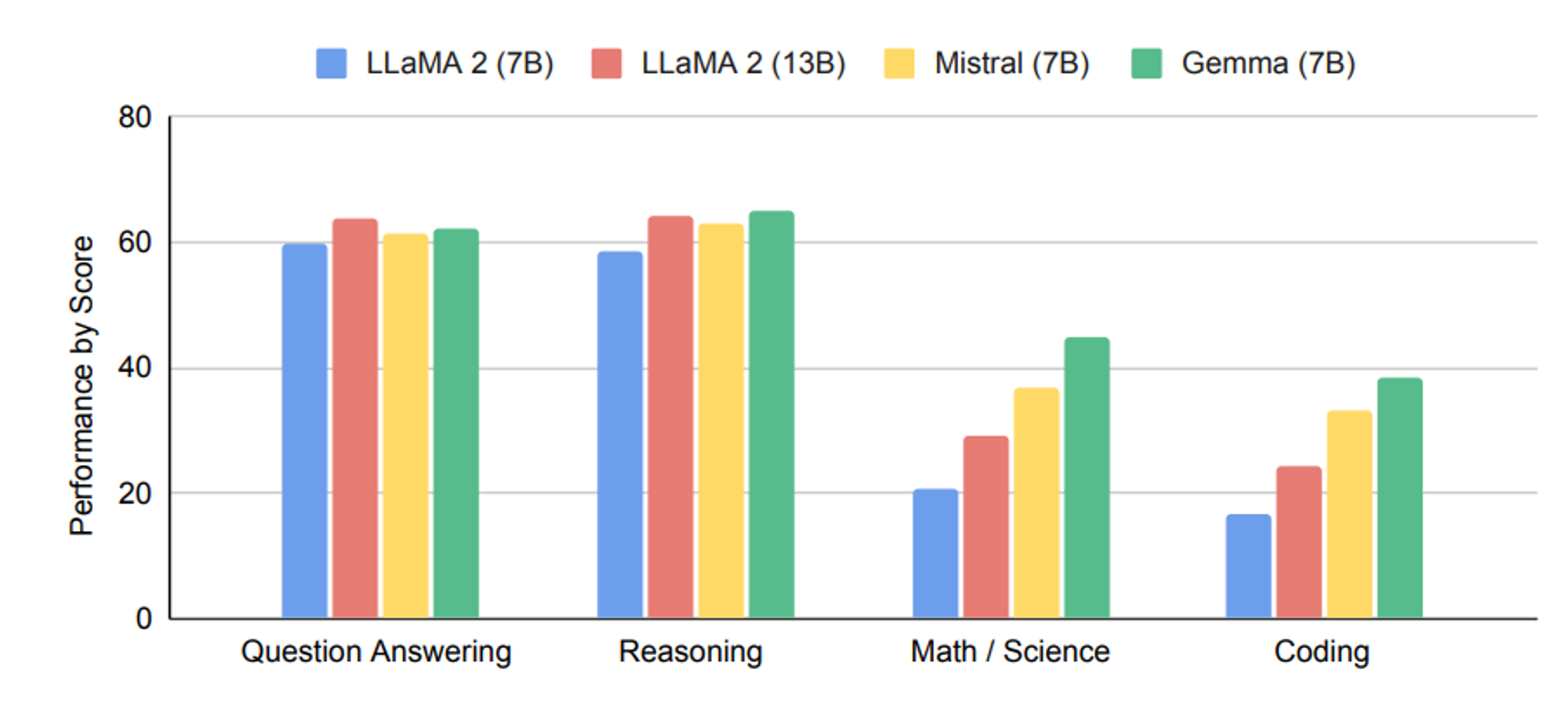
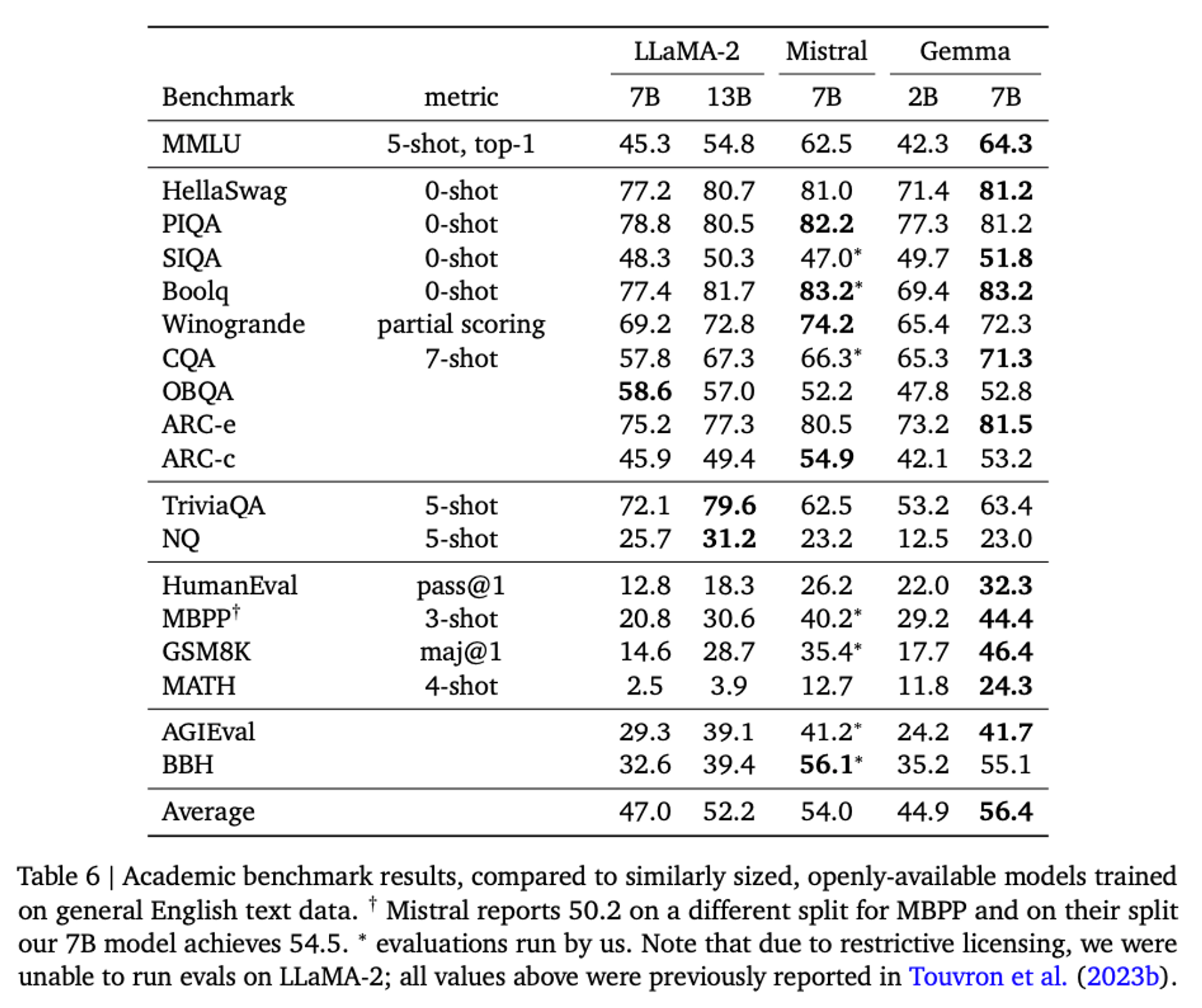
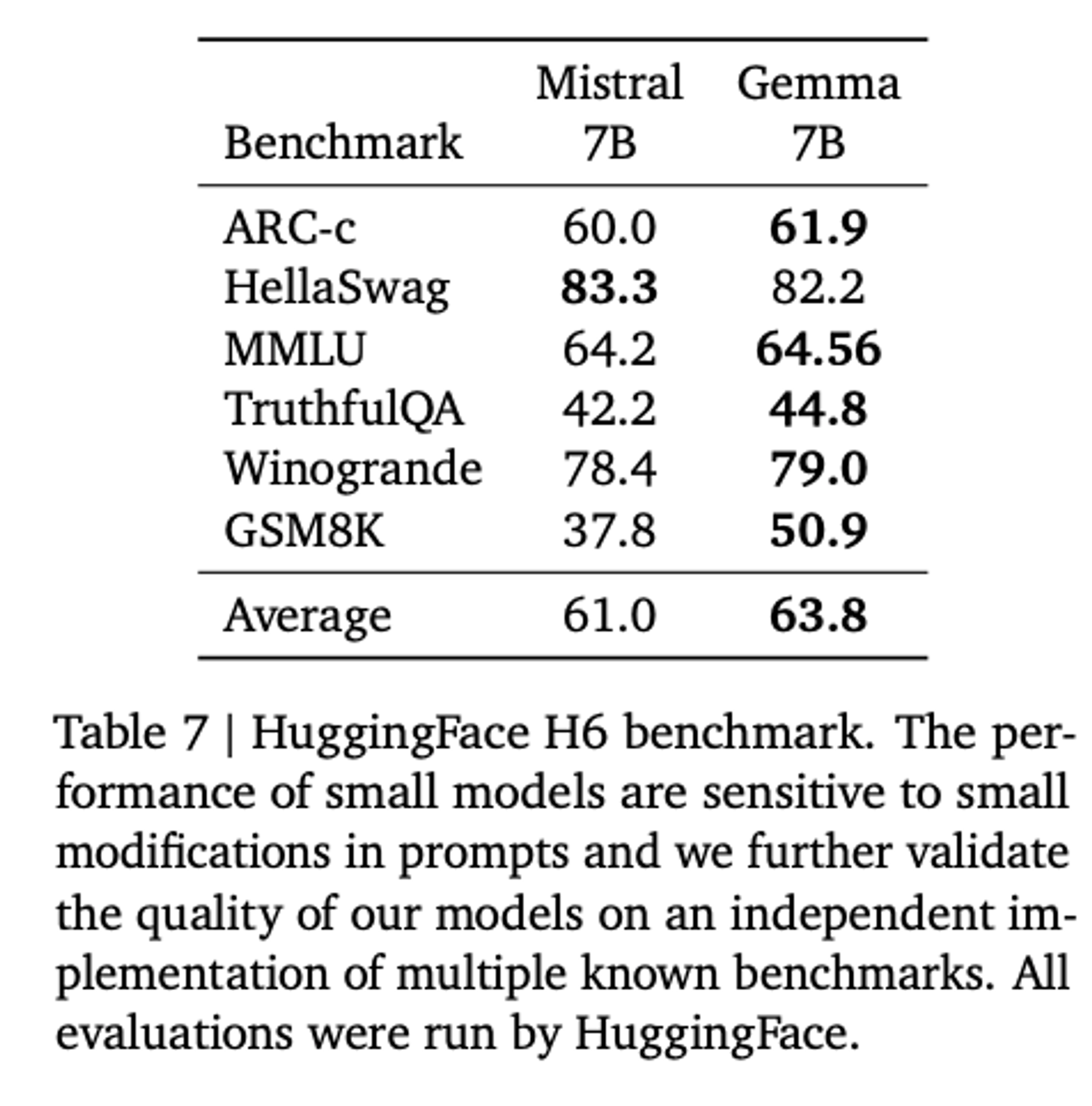
Limitation
Gemma 2B and 7B are trained on 2T and 6T tokens respectively of primarily-English data from
web documents, mathematics, and code. Unlike Gemini, these models are not multimodal, nor are they trained for state-of-the-art performance on multilingual tasks.