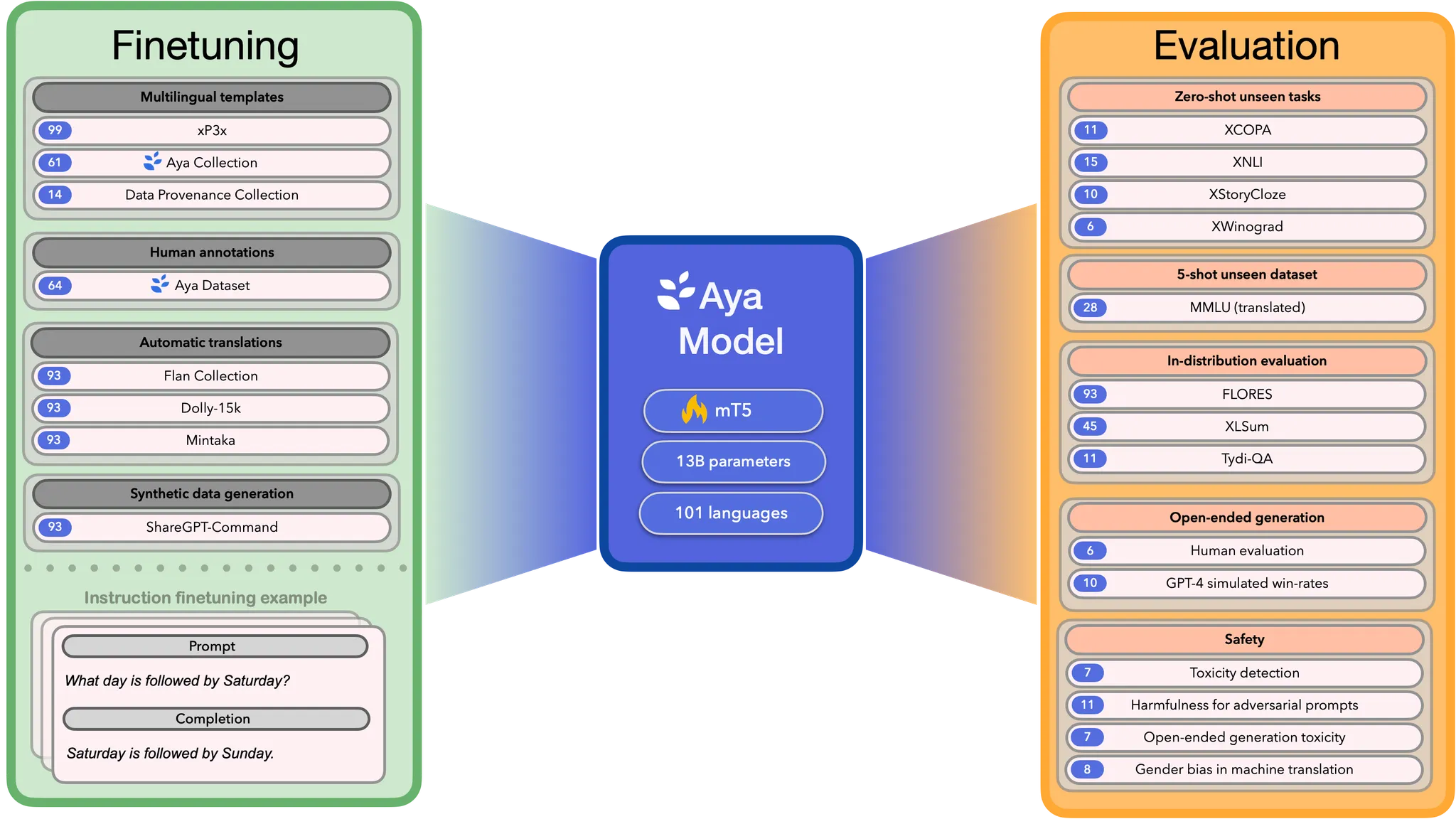
The Aya model is a massively multilingual generative language model that follows instructions in 101 languages. Aya outperforms mT0 and BLOOMZ a wide variety of automatic and human evaluations despite covering double the number of languages. The Aya model is trained using xP3x, Aya Dataset, Aya Collection, a subset of DataProvenance collection and ShareGPT-Command. We release the checkpoints under a Apache-2.0 license to further our mission of multilingual technologies empowering a multilingual world.

Question
•
ShareGPT-Command : It seems that ShareGPT is collecting output from ChatGPT. Using it to train or finetune a language, does it violate OpenAI's terms and conditions (https://openai.com/policies/terms-of-use, Section 2c)?
License: Apache 2.0
Features by Cohere For AI (C4AI)
•
13B parameters model — relatively small model
◦
Aya is built by fine-tuning 13B parameter mT5 model
•
Finetuning
◦
Architecture: Same as mt5-xxl
◦
Number of Samples seen during Finetuning: 25M
◦
Batch size: 256
◦
Hardware: TPUv4-128
◦
Software: T5X, Jax
•
101 languages supported — complete list here
Shortage


•
•
No public embedding-specific modelEmbedding model의 Base model로의 활용?
•
◦
Text → T5 encoder → the mean pooling
◦
objective function : in-batch sampled softmax loss w/ an additional negative sample & a bi-directional loss
◦
multi-stage training : web-mined corpus (semi-structured data) → search datasets (well-annotated; MS MARCO & NQ)
•
GTR 처럼 Encoder + pooling 방식으로 이용할 수 있음 (maybe 4.8B?)
•
️ No quantized version yet — requires > 24GB VRAM GPUMistral 7x8b : 46.7B params (12.9B active params)
•
Mistral 7x8b quantized down to 4b and running locally assumes I'm running a Debian-based system
•
️ Based on the mT5 architecture (multilingual T5), same as FLAN-T5. SOTA for multilingual tasks — translation etc. — performances might be lacking on other tasksProject Aya : https://aya.for.ai/
•
https://txt.cohere.com/aya-multilingual/ : it launched on 2023.06.05 under “not all languages have been treated equally by developers and researchers”

Much of the data used to train large language models comes from the internet, which continues to reflect the composition of early users of this technology - 5% of the world speaks English at home, yet 63.7% of internet communication is in English. There are around 7,000 languages spoken in the world, and around 400 languages have more than 1M speakers.1 However, there is scarce coverage of multilingual datasets.2 3
[1] How many languages are there in the world? https://www.ethnologue.com/insights/how-many-languages/
[2] From Zero to Hero: On the Limitations of Zero-Shot Language Transfer with Multilingual Transformers. (2023). Retrieved 30 May 2023, from https://aclanthology.org/2020.emnlp-main.363.pdf
[3] Team, N., Costa-jussà, M., Cross, J., Çelebi, O., Elbayad, M., & Heafield, K. et al. (2022). No Language Left Behind: Scaling Human-Centered Machine Translation. Retrieved 30 May 2023, from https://arxiv.org/abs/2207.04672
◦
In our commitment to fostering collaboration, we are supporting a dedicated Discord server to connect with Aya contributors worldwide
•
A global initiative led by Cohere For AI involving over 3,000 independent researchers across 119 countries. Aya is a state-of-art model and dataset, pushing the boundaries of multilingual AI for 101 languages through open science.

◦
1 Model : Aya is built by fine-tuning 13B parameter mT5 model
◦
513M total Release Dataset Size
▪
This massive collection was created by fluent speakers around the world creating templates for selected datasets and augmenting a carefully curated list of datasets. It also includes the Aya Dataset which is the most extensive human-annotated, multilingual, instruction fine-tuning dataset to date.
◦
3k indep. Researchers
◦
56 Language Ambassadors
◦
119 Countries
◦
204K original Human Annotations
▪
204,000 rare human curated annotations by fluent speakers in 67 languages
◦
101 Languages
◦
31K discord messages
•
◦
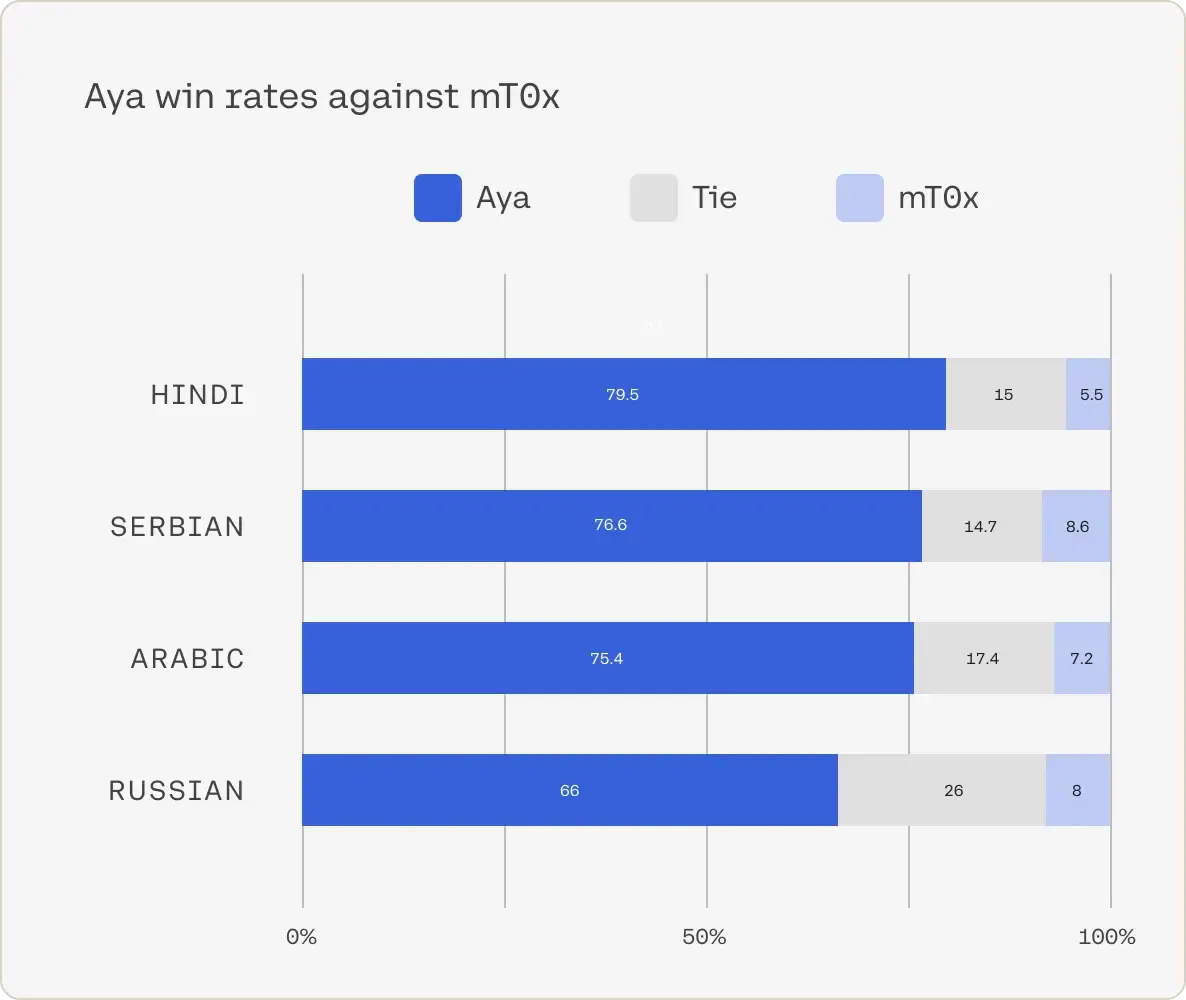
HUMAN EVALUATION OF THE AYA MODEL SHOWS CONSISTENT GAINS : significantly higher quality than mT0x ⇒ Based on human evaluations from professional annotators who compared model responses to instructions given in multiple languages, the Aya model is preferred 77% of the time on average.
◦
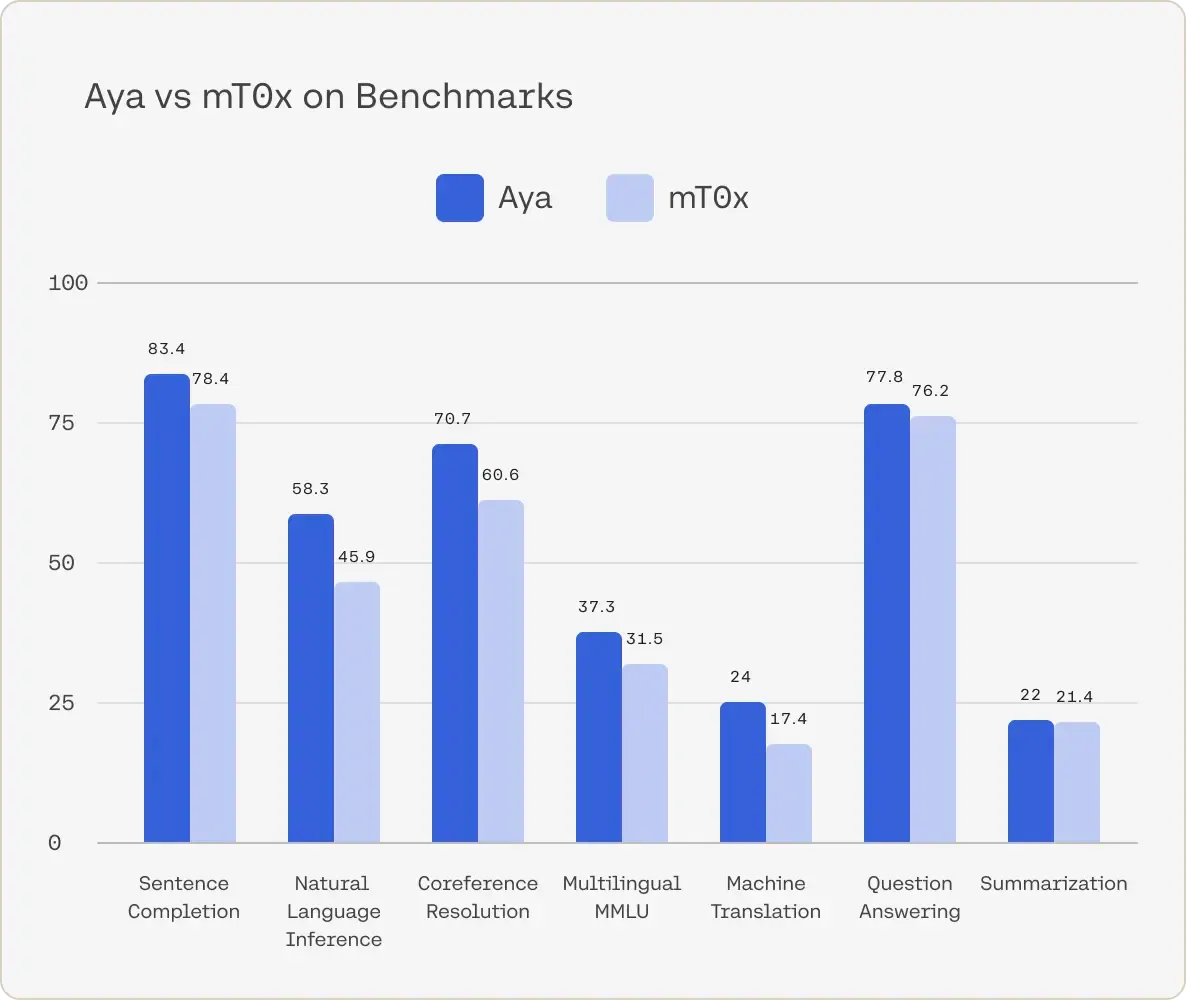
LEADING PERFORMANCE : The Aya model achieves superior performance compared to mT0x across multilingual benchmarks. These benchmarks cover a range of tasks, including unseen and in-distribution generative tasks, across 100 languages. The Aya model consistently outperforms mT0x in all tasks showing its superior multilingual capabilities across various types of tasks.
◦
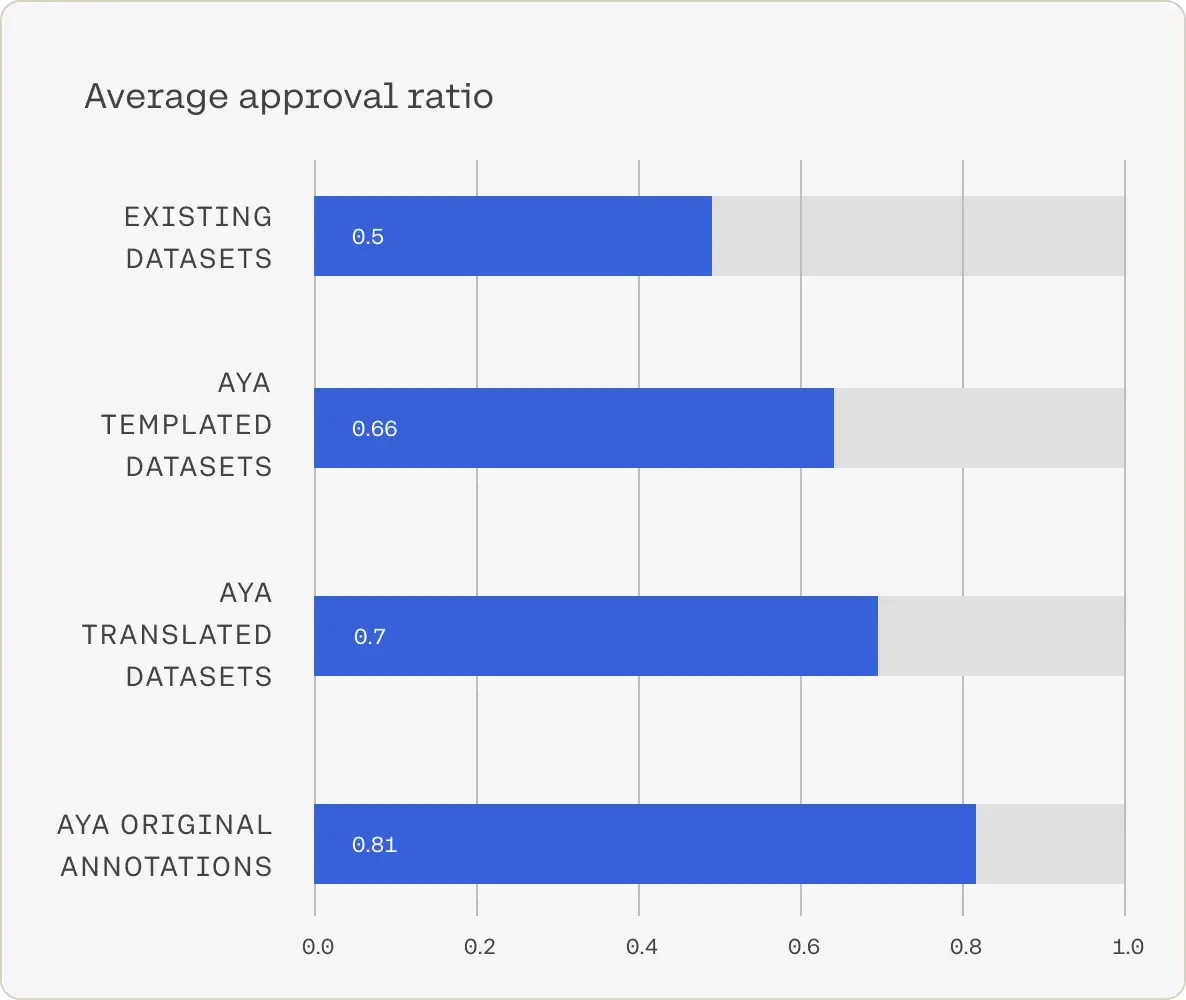
High Quality Dataset : The quality of instruction data significantly influences the performance of the fine-tuned language model. Through a global assessment, we engaged annotators to evaluate the quality of various data collections, revealing that the Aya original annotations garnered the highest approval ratings from native and fluent speakers.
Aya model paper : https://arxiv.org/abs/2402.07827
•
Model download (huggingface) : https://huggingface.co/CohereForAI/aya-101
•
Refer to also https://replicate.com/zsxkib/aya-101/readme
Aya dataset paper : https://arxiv.org/abs/2402.06619
1. Aya collection : https://huggingface.co/datasets/CohereForAI/aya_collection
•
The Aya Collection is a massive multilingual collection consisting of 513 million instances of prompts and completions covering a wide range of tasks. This collection incorporates instruction-style templates from fluent speakers and applies them to a curated list of datasets, as well as translations of instruction-style datasets into 101 languages. Aya Dataset, a human-curated multilingual instruction and response dataset, is also part of this collection. See our paper for more details regarding the collection.
1.
Templated data: We collaborated with fluent speakers to create templates that allowed for the automatic expansion of existing datasets into various languages.
2.
Translated data: We translated a hand-selected subset of 19 datasets into 101 languages (114 dialects) using the NLLB 3.3B parameter machine translation model.
3.
Aya Dataset: We release the Aya Dataset as a subset of the overall collection. This is the only dataset in the collection that is human-annotated in its entirety.
2. Aya Dataset (included in Aya Collection) : https://huggingface.co/datasets/CohereForAI/aya_dataset
•
The Aya Dataset is a multilingual instruction fine-tuning dataset curated by an open-science community via Aya Annotation Platform from Cohere For AI. The dataset contains a total of 204k human-annotated prompt-completion pairs along with the demographics data of the annotators.
•
Language(s): 65 languages (71 including dialects & scripts).
3. Aya evaluation suite (Eval Set) : https://huggingface.co/datasets/CohereForAI/aya_evaluation_suite
•
Aya Evaluation Suite contains a total of 26,750 open-ended conversation-style prompts to evaluate multilingual open-ended generation quality. To strike a balance between language coverage and the quality that comes with human curation, we create an evaluation suite that includes:
1.
human-curated examples in 7 languages (tur, eng, yor, arb, zho, por, tel) → aya-human-annotated.
2.
machine-translations of handpicked examples into 101 languages → dolly-machine-translated.
3.
human-post-edited translations into 6 languages (hin, srp, rus, fra, arb, spa) → dolly-human-edited.
•
xP3x (Crosslingual Public Pool of Prompts eXtended) is a collection of prompts & datasets across 277 languages & 16 NLP tasks. It contains all of xP3 + much more! It is used for training future contenders of mT0 & BLOOMZ at project Aya @C4AI
•
The dataset can be recreated using instructions available here (https://github.com/bigscience-workshop/xmtf#create-xp3) together with the file in this repository named xp3x_create.py. We provide this version to save processing time.
◦
Languages: 277
•
Family Datasets
Name | Explanation | Example models |
Mixture of 17 tasks in 277 languages with English prompts | ||
Mixture of 13 training tasks in 46 languages with English prompts | ||
Mixture of 13 training tasks in 46 languages with prompts in 20 languages (machine-translated from English) | ||
xP3 + evaluation datasets adding an additional 3 tasks for a total of 16 tasks in 46 languages with English prompts | ||
Megatron-DeepSpeed processed version of xP3 | ||
5. DataProvenance Collection : https://huggingface.co/datasets/DataProvenanceInitiative/Commercially-Verified-Licenses
•
A wave of recent language models have been powered by large collections of natural language datasets. The sudden race to train models on these disparate collections of incorrectly, ambiguously, or under-documented datasets has left practitioners unsure of the legal and qualitative characteristics of the models they train. To remedy this crisis in data transparency and understanding, in a joint effort between experts in machine learning and the law, we’ve compiled the most detailed and reliable metadata available for data licenses, sources, and provenance, as well as fine-grained characteristics like language, text domains, topics, usage, collection time, and task compositions. Beginning with nearly 40 popular instruction (or “alignment”) tuning collections, we release a suite of open source tools for downloading, filtering, and examining this training data. Our analysis sheds light on the fractured state of data transparency, particularly with data licensing, and we hope our tools will empower more informed and responsible data-centric development of future language models.
•
Constituent Data Collections
◦
Following table shows each constituent data collection this Dataset along with original source from where each data collection is derived from.
# | Collection Name | Description | Source |
1 | Anthropic HH-RLHF | Human preference data about helpfulness and harmlessness & Human-generated and annotated red teaming dialogues. | |
2 | CommitPackFT | CommitPackFT is a 2GB filtered version of CommitPack to contain only high-quality commit messages that resemble natural language instructions. | |
3 | Dolly 15k | Databricks Dolly 15k is a dataset containing 15,000 high-quality human-generated prompt / response pairs specifically designed for instruction tuning large language models. | |
4 | Flan Collection (Chain-of-Thought) | Chain-of-Thought sub-mixture in Flan collection dataset. | |
5 | Flan Collection (Dialog) | Chain-of-Thought sub-mixture in Flan collection dataset. | |
6 | Flan Collection (Flan 2021) | Flan 2021 sub-mixture in Flan collection dataset. | |
7 | Flan Collection (P3) | P3 sub-mixture in Flan collection dataset. | |
8 | Flan Collection (Super-NaturalInstructions) | Super-Natural Instructions in Flan collection dataset. | |
9 | Joke Explanation | Corpus for testing whether your LLM can explain the joke well. | |
10 | OIG | Open Instruction Generalist is a large instruction dataset of medium quality along with a smaller high quality instruction dataset (OIG-small-chip2). | |
11 | Open Assistant | OpenAssistant Conversations (OASST1) is a human-generated, human-annotated assistant-style conversation corpus consisting of 161,443 messages in 35 different languages, annotated with 461,292 quality ratings, resulting in over 10,000 fully annotated conversation trees. | |
12 | Open Assistant OctoPack | Filtered version of OpenAssistant Conversations (OASST1) to focus only on high-quality conversation trees as used in OctoPack paper. | |
13 | Tasksource Symbol-Tuning | Tasksource datasets converted for symbol-tuning. | |
14 | Tasksource Instruct | Tasksource datasets as instructions for instruction-tuning. | |
15 | xp3x | xP3x is a collection of prompts & datasets across 277 languages & 16 NLP tasks. It contains all of xP3 + much more. | |
16 | StarCoder Self-Instruct | Dataset generated by prompting starcoder to generate new instructions based on some human-written seed instructions. |