Junseong’s AI Blog
/
LLM Ecosystem: Open-Source Model/Data/Code (since ChatGPT)
/
koalpaca
Search
koalpaca
Affiliation
Seoul National Univ.
Commercial
Fine-tuning Method
SFT
Note
-
github
- finetuning base models : LLAMA LoRA (13B, 30B, 65B), Polyglot-ko fine-tuning (5.8B), LLAMA fine-tuning (7B) - Alpaca와 동일한 modified self-instruct
데이터
-
Koalpaca Instruct Data
. Alpaca data 중 input만 한국어로 번역 . GPT 3.5 (
ChatGPT
) 로 한국어 답변 생성 (
self-instruct
방식) . n=10으로 생성하는 것이 가장 안정적
모델 크기
5.8B (Polyglot-ko fine-tuning) 7B (LLAMA fine-tuning) 13B (LLAMA LoRA) 30B (LLAMA LoRA) 65B (LLAMA LoRA)
새롭게 제공된 Resource
Model
InstructData
출시일
2023-03
시스템 prompt
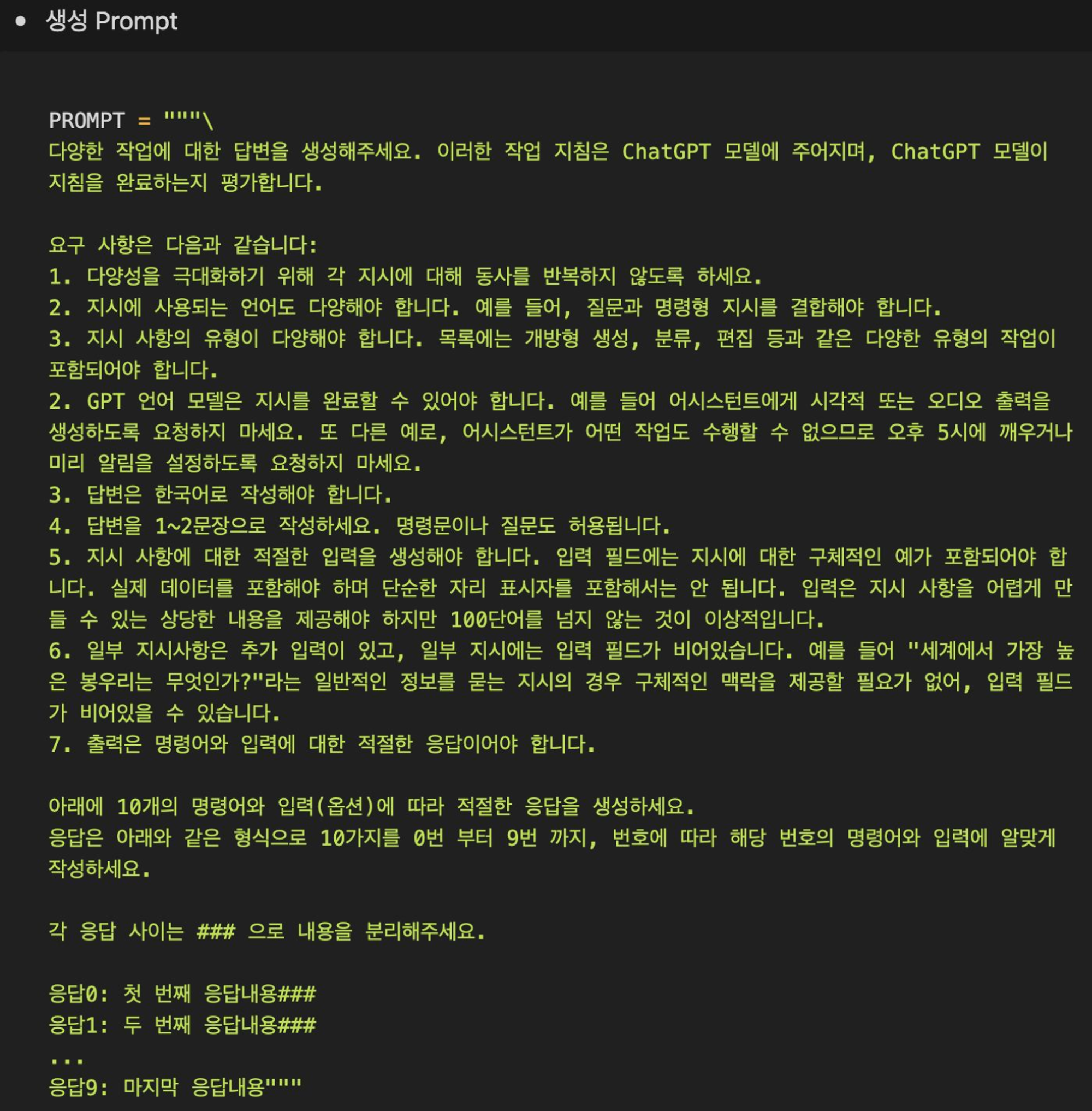
생성 prompt