Full-fledged RLHF Training Pipeline
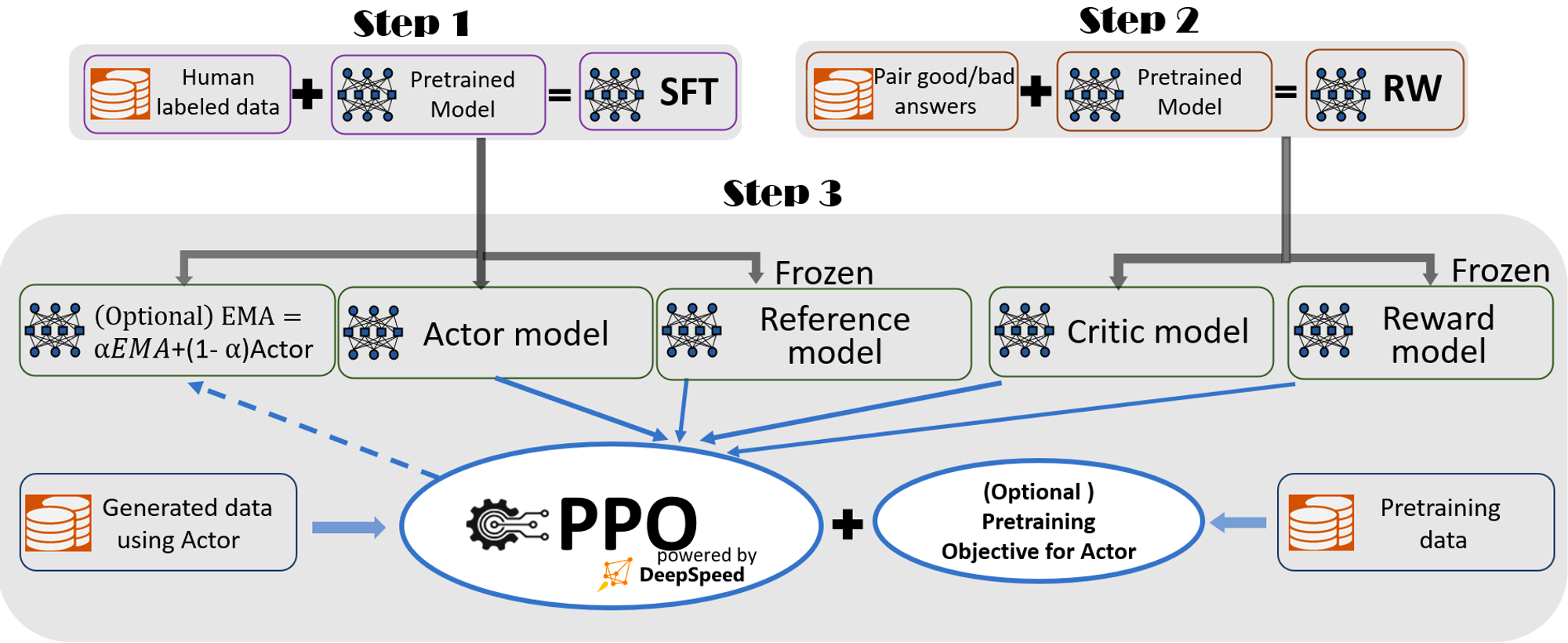
Our pipeline includes three main steps:
•
Step 1: Supervised finetuning (SFT), where human responses to various queries are carefully selected to finetune the pretrained language models.
•
Step 2: Reward model finetuning, where a separate (usually smaller than the SFT) model (RW) is trained with a dataset that has human-provided rankings of multiple answers to the same query.
•
Step 3: RLHF training, where the SFT model is further finetuned with the reward feedback from the RW model using the Proximal Policy Optimization (PPO) algorithm.
We provide two additional features in Step 3 to help improve model quality:
•
Exponential Moving Average (EMA) collection, where an EMA based checkpoint can be chosen for the final evaluation.
•
Mixture Training, which mixes the pretraining objective (i.e., the next word prediction) with the PPO objective to prevent regression performance on public benchmarks like SQuAD2.0.
according to InstructGPT, EMA checkpoints generally provide better response quality than conventional final trained model and Mixture Training can help the model retain the pre-training benchmark solving ability. As such, we provide them for users to fully get the training experience as described in InstructGPT and strike for higher model quality.
In addition to being highly consistent with InstructGPT paper, we also provide convenient features to support researchers and practitioners to train their own RLHF model with multiple data resources:
•
Data Abstraction and Blending Capabilities: DeepSpeed-Chat is able to train the model with multiple datasets for better model quality. It is equipped with (1) an abstract dataset layer to unify the format of different datasets; and (2) data splitting/blending capabilities so that the multiple datasets are properly blended then split across the 3 training stages.
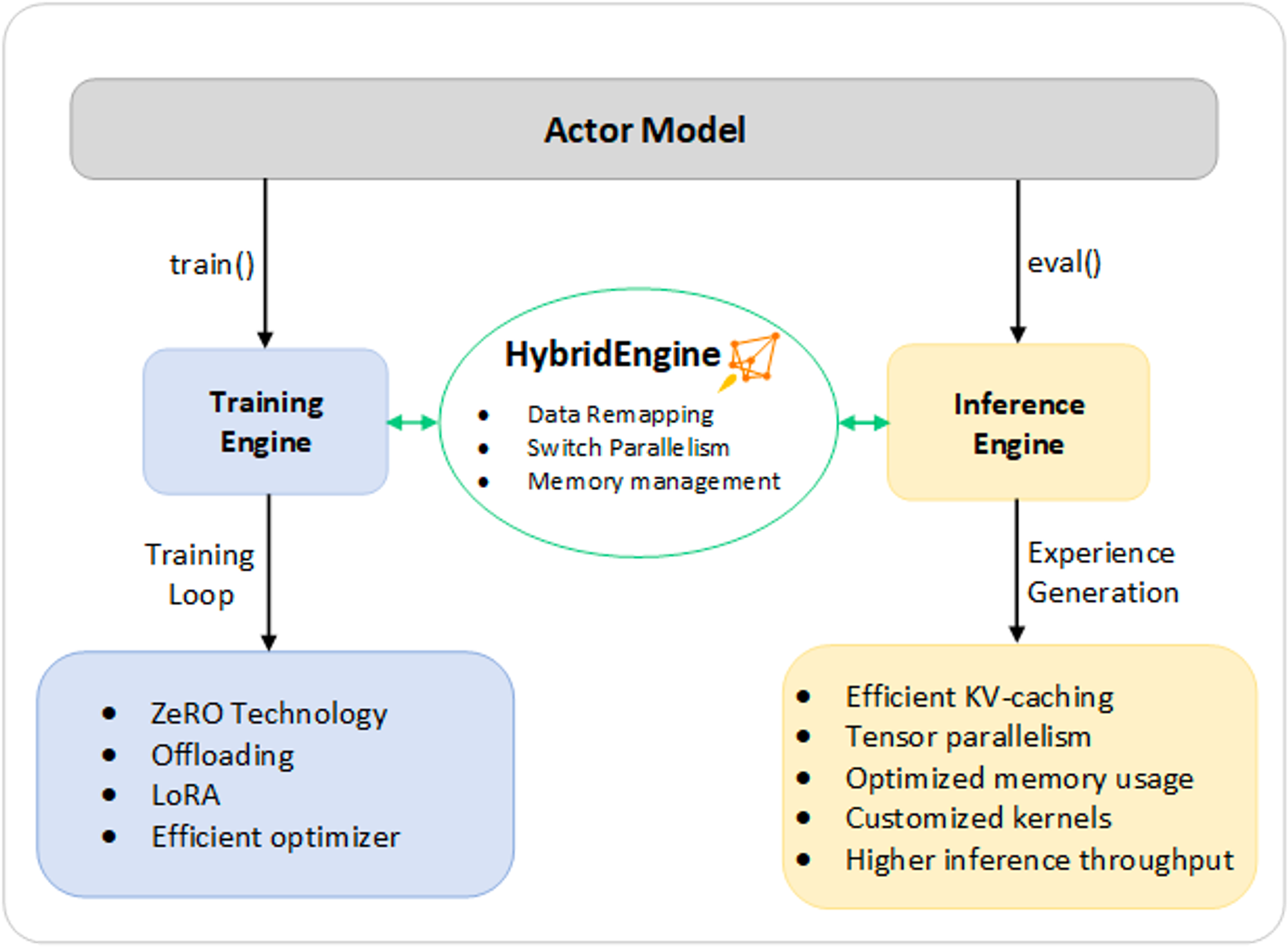
Step 3 (RLHF training) 에서의 Hybrid Engine
Each iteration requires efficient processing of two phases a) inference phase for token/experience generation, producing inputs for the training and b) training phase to update the weights of actor and reward models, as well as the interaction and scheduling between them.
two major costs: (1) the memory cost, as several copies of the SFT and RW models need to be served throughout stage 3; and (2) the predominant generation phase, which if not accelerated properly, will significantly slow down the entire stage 3. Additionally, the two important features we added in Stage 3, including Exponential Moving Average (EMA) collection and Mixture Training, will incur additional memory and training costs.
inference engine과 training engine을 동시에 제공하되, 각각에 맞는 optimization technique 이용
•
Inference : a light-weight memory management system (KV-cache & intermediate results)
◦
highly-optimized inference-adapted kernels
◦
tensor parallelism implementation (model partitioning)
•
Training : memory optimization techniques
◦
ZeRO family (sharding) (model partitioning) & LoRA
⇒ avoid memory allocation bottlenecks & support large batch sizes