References


•
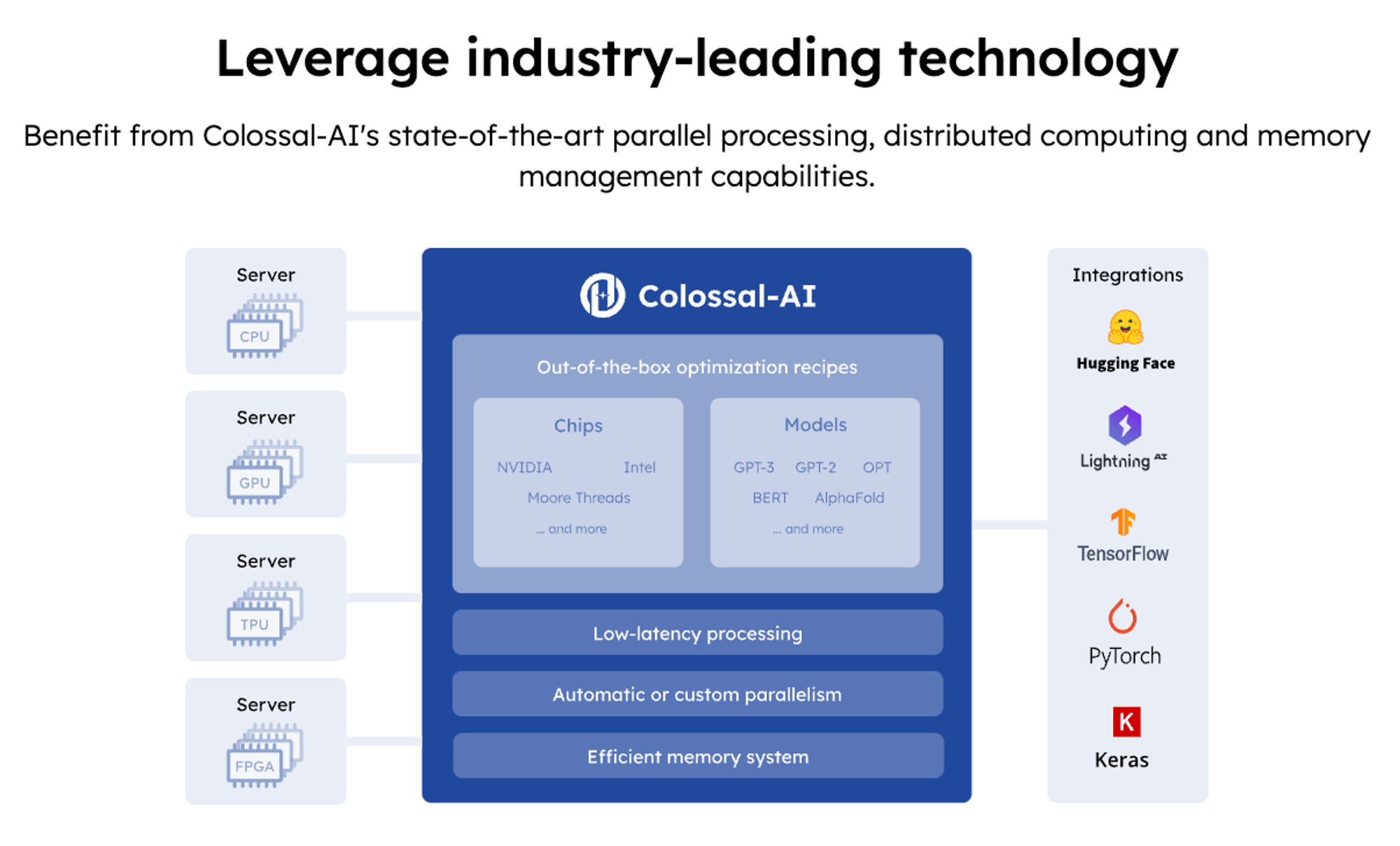
Github :  ColossalAI
ColossalAI
•
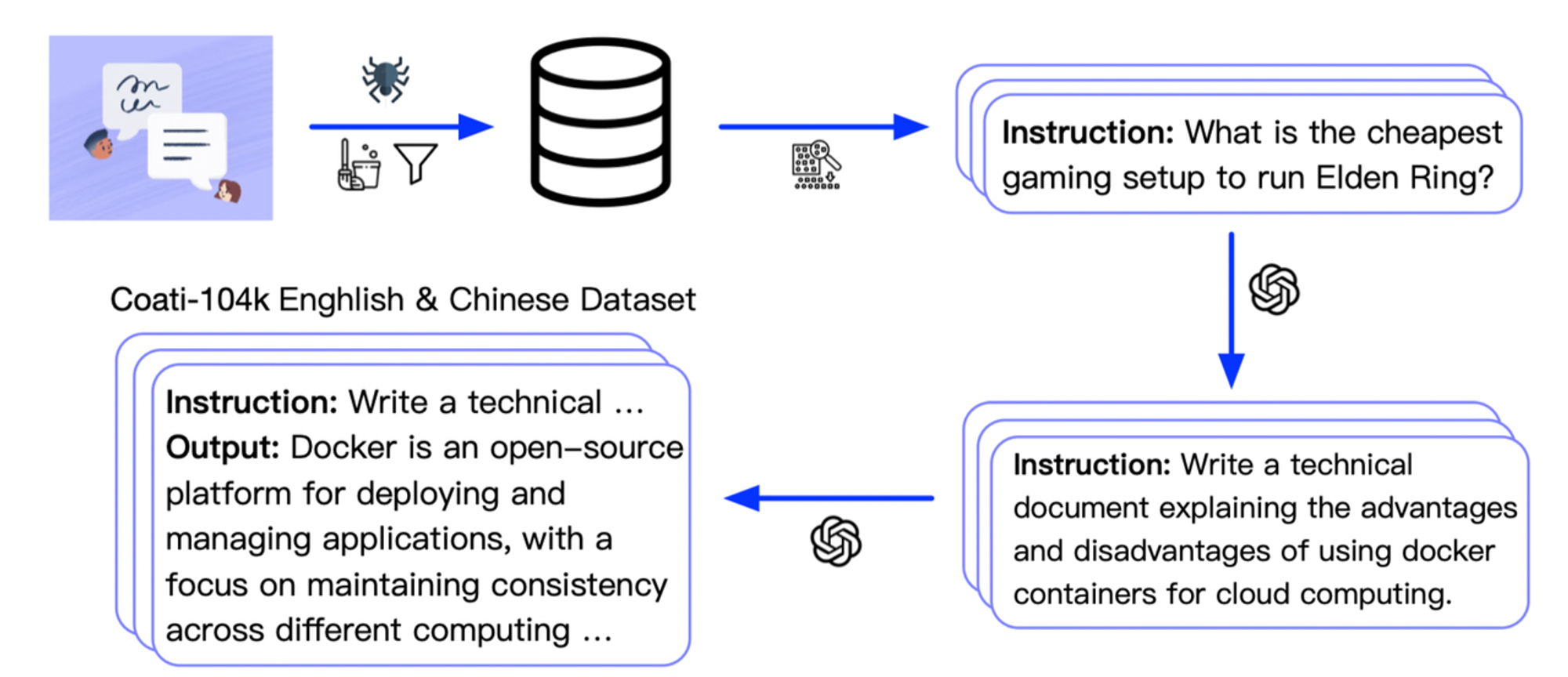
ColossalChat github : https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat
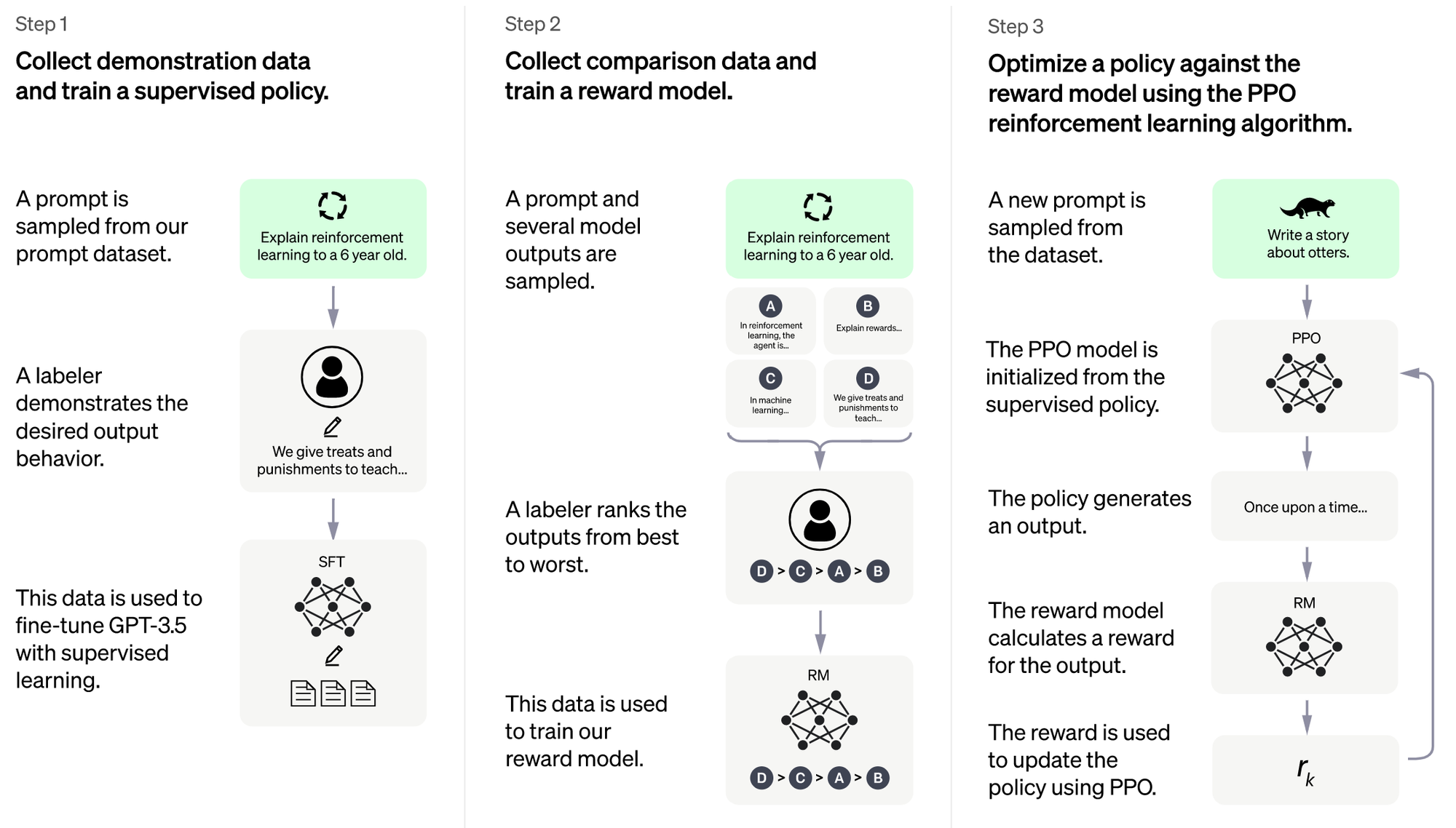
RLHF

Zero + Gemini to Reduce Memory Redundancy
Colossal-AI supports ZeRO (Zero Redundancy Optimizer) to improve memory usage efficiency, enabling larger models to be accommodated at a lower cost, without affecting computing granularity and communication efficiency.
The automatic chunk mechanism can further improve ZeRO’s performance by increasing memory usage efficiency, reducing communication frequency, and avoiding memory fragmentation.
The heterogeneous memory space manager, Gemini, supports unloading optimizer states from GPU memory to CPU memory or hard disk space to overcome the limitations of GPU memory capacity, expand the scale of trainable models, and reduce the cost of large AI model applications.